网站平台建设呈现全新亮点深圳网站制作设计
线程池和ThreadLocal详解
- 线程池
- 池化模式:
- 线程池里的线程数量设定为多少比较合适?
- 添加线程规则:
- 实现原理:
- 线程池实现任务复用的原理
- 线程池状态:
- Executors 创线程池工具类
- 手动创建(更推荐):
- 自动创建:
- ExecutorService 执行线程池
- 运行:
- 关闭:
- 其他:
- execut() 执行流程:
- 钩子方法
- ThreadLocal
- 优点:
- 创建:
- 使用场景
- 一、每个线程需要一个独享的对象
- 二、每个线程内需要保存全局变量(例如在拦截器中获取用户信息)
- 原理
- 注意
- 内存泄漏:
- 如何避免内存泄露(阿里规约)
- 空指针异常:
线程池
java线程池是 JDK1.5提供 juc(java.util.concurrent)包中,底层实现其实就是 Callable 和 Future 接口

池化模式:
- 将大量我们需要的对象提前创建好,放在一个池(概念),对象提前创建完成,也不需要销毁对象,所以说使用效率比较好。
- 优点:使用效率较好,避免对象的 重复创建 和 销毁。
- 缺点:内存占有较高,池的数量难以把控。
线程池里的线程数量设定为多少比较合适?
- CPU 密集型(加密、计算hash等)︰最佳线程数为CPU核心数的 1-2 倍左右。
- 耗时 IO 型(读写数据库、文件、网络读写等)︰最佳线程数一般会大于 CPU 核心数很多。
- 参考 Brain Goetz 推荐的计算方法︰线程数 = CPU核心数 * (1+平均等待时间/平均工作时间)
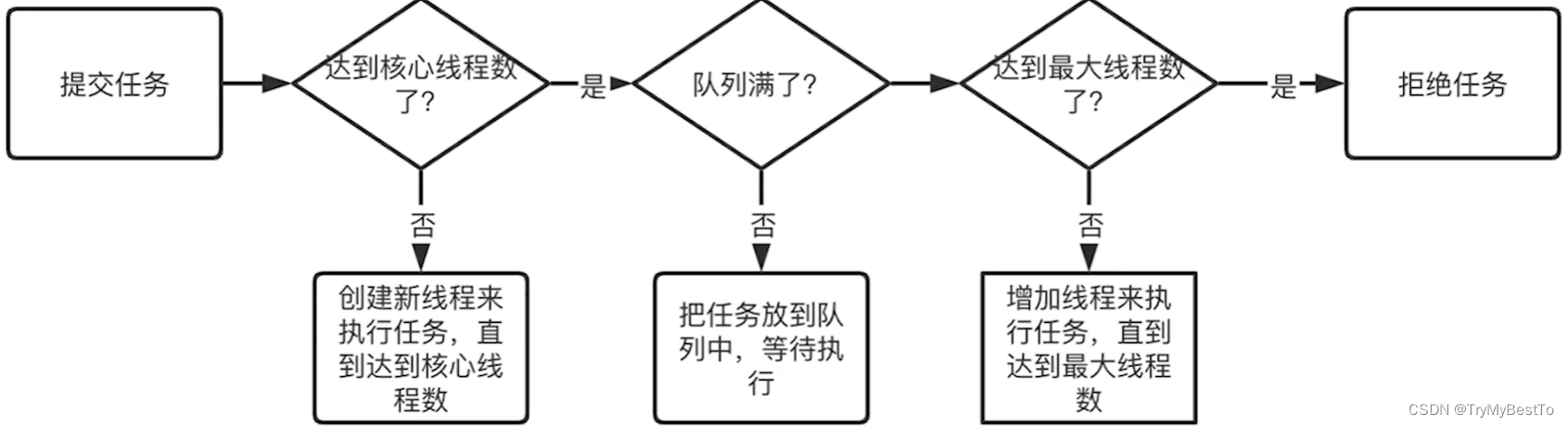
添加线程规则:
- 最开始线程总数小于 corePoolSize 时,即使有线程处于空闲状态新任务到来时,也会创建一个新线程。
- 直到线程数等于 corePoolSize,再来任务时,会把任务放入队列去等待。
- 直到队列也满了,如果此时线程数小于 maximumPoolSize,则会再创建新线程来执行任务。
- 如果队列已满,并且线程数已经扩大到等于 maximumPoolSize时,再尝试添加任务时,会被拒绝。
- 特点:
- 若 corePoolSize == maximumPoolSize,则相当于 newFixedThreadPool();
- 线程池希望保持较少的线程数,并且只有在负载变得很大时才增加它。
- 只有在队列填满时才创建多于corePoolSize的线程,如果使用的是无界队列,那么线程数就不会超过 corePoolSize。
实现原理:
- 线程池组成部分
- 线程池管理器
- 工作线程
- 任务队列
- 任务接口(Task)
线程池实现任务复用的原理
- 相同线程执行不同任务
- 不需要重复的启动线程,循环的从队列中取出新任务并执行其 run() 方法。
线程池状态:
- RUNNING:接受新任务 并 处理排队任务。
- SHUTDOWN:不接受新任务,但处理排队任务。
- STOP:不接受新任务,也不处理排队任务,并中断正在进行的任务。
- TIDYING:所有任务都已终止,workerCount 为零时,线程会转换到 TIDYING 状态,并将运行 terminate() 钩子方法。
TERMINATED:terminate()钩子方法 运行完成。
Executors 创线程池工具类
- 根据情况,我们创建很多种不同场景的线程池 Executors.new…();
- 创建线程池返回 ExecutorService 类对象。
手动创建(更推荐):
new ThreadPoolExecutor(7个参数)
-
最原始的线程池,所有其他的线程池底层都是用的此线程池实现的。
-
前== 五个参数 ==为必须参数,面试题经常考问!!!
-
1、 corePoolSize:核心线程数,线程池中始终存活的线程数。
-
2、 maximumPoolSize:最大线程数
- 线程池中允许的最大线程数,当线程池的任务队列满了之后可以创建的最大线程数。
-
3、 keepAliveTime:最大线程数可以存活的时间
- 如果线程池当前的线程数多于 corePoolSize,那么如果多余的线程空闲时间超过 keepAliveTime,它们就会被终止。
-
4、unit:时间单位是和参数 3 存活时间配合使用的,合在一起用于设定线程的存活时间 ,参数 keepAliveTime 的时间单位有以下 7 种可选:
- TimeUnit.DAYS:天; TimeUnit.HOURS:小时; TimeUnit.MINUTES:分; TimeUnit.SECONDS:秒
- TimeUnit.MILLISECONDS:毫秒; TimeUnit.MICROSECONDS:微妙; TimeUnit.NANOSECONDS:纳秒
-
5、 workQueue:一个阻塞队列,用来存储线程池等待执行的任务,均为线程安全,它包含以下 7 种类型:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:一个由链表结构组成的无界阻塞队列。
- SynchronousQueue:直接交接,一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
- DelayQueue:延迟队列:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
- LinkedTransferQueue : 一个由链表结构组成的无界阻塞队列,与 SynchronousQueue 类似,还含有非阻塞方法。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
-
6、threadFactory:线程工厂,主要用来创建线程。
- 默认为正常优先级、非守护线程(Executors.defaultThreadFactory())。
- 创建出来的线程都在同一个线程组。
- 如果自己指定 ThreadFactory,那么就可以改变线程名、线程组、优先级、是否是守护线程等。
-
7、handler:拒绝策略,拒绝处理任务时的策略,系统提供了 4 种可选
- AbortPolicy:默认策略,拒绝并直接抛出异常。
- DiscardPolicy:默默的丢弃任务,不会通知。
- DiscardOldestPolicy:丢弃队列中存在时间最久的任务。
- CallerRunsPolicy:让提交任务的线程去执行。
- 优点:不会放弃执行任务,并且能够使提交任务的速度降低下来(负反馈)
-
很多公司都 【强制使用】 这个最原始的方式创建线程池,因为这是可控的。
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(500, 2000, 1, TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>());
自动创建:
- Executors.newFixedThreadPool(int n):创建一个 可重用固定大小 的线程池,可控制并发的线程数,超出的线程会在队列中等待。
- 适用场景:并发量不会发生变化(并发量的变化非常小)
new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
- Executors.newCachedThreadPool([int n]):创建一个== 可缓存 ==的线程池。
- 若线程数超过处理所需,缓存一段时间后会回收,若线程数不够,则新建线程。
- 适用场景:并发量变化比较明显,建议使用此方法
new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
- ScheduledExecutorService Executors.newScheduledThreadPool(): 创建 延迟 后的线程池,可以设置间隔。
- 返回 ScheduledExecutorService类 对象:
- schedule(Runnable command, long delay, TimeUnit unit):指定延迟时间后创建线程。
- scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit):
- 在给定的初始延迟后首先启用,然后根据间隔时间 period 执行。
- 返回 ScheduledExecutorService类 对象:
(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new DelayedWorkQueue());
- Executors.newSingleThreadExecutor(): 单线程的线程池,只会用唯一的工作线程来执行任务。
new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
- Executors.newWorkStealingPool():创建一个抢占式执行的线程池(任务执行顺序不确定)
- 注意此方法只有在 JDK 1.8+ 版本中才能使用。
ExecutorService 执行线程池
运行:
- execute(Runnable task):运行线程。
- submit():运行线程(更加强大),常用于创建Runnable匿名内部类

ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {final int idx = i;executor.submit(() -> System.out.println(Thread.currentThread().getName() + "————》" + idx));
}
关闭:
- shutdown():拒绝新任务,等 正在执行 以及 阻塞队列 中的任务执行完毕后就停止线程池。
- isShutdown():判断线程池是否已经开始了关闭工作,也就是是否执行了 shutdown 或者 shutdownNow 方法。。
- IsTerminated():判断线程池是否已经完全终止。(正在执行、阻塞队列都已清空)
- awaitTermination(long timeout, TimeUnit unit):检测在指定时间内(此时当前线程阻塞),线程池是否会完全终止。
- List< Runnable> shutdownNow():立刻完全停止线程池,中断正在执行的线程,并将阻塞队列里的线程返回。
- 线程 run() 方法在运行期间被中断会抛出 InterruptedException,可以使用 catch 捕获。
其他:
- BlockingQueuegetQueue():获取阻塞队列
execut() 执行流程:
public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// 线程池正在运行,且队列没满if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 线程停止运行了,则删除任务,并拒绝if (! isRunning(recheck) && remove(command))reject(command);// 核心工作线程没有了,创建一个空的核心工作线程else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 队列满了,尝试添加额外线程,此处 false 代表添加的是额外线程(<= 最大线程数)else if (!addWorker(command, false))reject(command);
}
钩子方法
-
在每个任务执行前后进行操作
- 例如:日志、统计、暂停
-
继承自线程池 ThreadPoolExecutor ,并重写构造器
-
可重写方法:
- beforeExecute():线程执行前的操作。
- afterExecute():线程执行后的操作。
示例:实现线程池的暂停、恢复操作,(省略了构造器)
public class PauseableThreadPool extends ThreadPoolExecutor {// 线程池是否处于暂停状态private boolean isPaused;private final ReentrantLock lock = new ReentrantLock();private Condition unPaused = lock.newCondition();public void pause() {lock.lock();try {isPaused = true;} finally {lock.unlock();}}@Overrideprotected void beforeExecute(Thread t, Runnable r) {super.beforeExecute(t, r);lock.lock();try {while (isPaused) {unPaused.await();}} catch (InterruptedException e) {throw new RuntimeException(e);} finally {lock.unlock();}}public void resume() {lock.lock();try {isPaused = false;unPaused.notifyAll();} finally {lock.unlock();}}
}
ThreadLocal
-
在 JDK1.2 的版本中已经为线程对象提供了副本对象,特点是:每一个线程都 独立拥有 ThreadLocal 对象。
-
作用1:在任何线程的方法中都可以轻松获取到该对象。
在 ThreadLocal 初始化时加入对象。 -
作用2:让某个需要用到的对象在线程间隔离(每个线程都有自己的独立的对象)
在线程中 set 对象。 -
ThreadLocal 不支持继承性
- 同一个 ThreadLocal 变量在父线程中被设置值后,那么在子线程中是获取不到的。
-
InheritableThreadLocal 类是可以做到支持继承性。
优点:
- 达到线程安全。
- 不需要加锁,提高执行效率。
- 更高效地利用内存、节省开销。
- 相比于场景一每个任务都新建一个 SimpleDateFormat,显然用 ThreadLocal 可以节省内存和开销
- 免去传参的繁琐
- 不需要每次都传同样的参数
- ThreadLocal使得代码耦合度更低,更优雅
创建:
- 一定要将 ThreadLocal 定义成 静态变量 static
- ThreadLocal 需要一个泛型;
public static ThreadLocal<String> threadLocal1 = new Thread<>();
public static ThreadLocal<SimpleDateFormat> threadLocal2 = ThreadLocal.withInitial(() ->new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
); // 初始化并设置值
-
get():获取 ThreadLocal 中当前线程共享的变量的值。
- 在 线程开启(或调用 remove())后第一次调用 get() 的时候,会调用 initialValue() 来得到值。
-
remove():移除 ThreadLocal中当前线程共享的变量的值。
- 最后 一定 要移除值!!!,否则很容易出现 内存溢出。
-
initialValue():该方法会返回当前线程对应的 “初始值”,这是一个延迟加载的方法。默认为 null。
- ThreadLocal.withInitial():初始化 ThreadLocal 并设置 initialValue()。
-
set():设置 ThreadLocal 中当前线程共享的变量的值。
-
set 和 setInitialValue 结果都是调用 map.set,只不过是起点和入口不一样。
public static ThreadLocal<SimpleDateFormat> threadLocal2 = ThreadLocal.withInitial(() ->new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
);
@Test
void contextLoads() {ExecutorService executorService = Executors.newFixedThreadPool(10);for (int i = 0; i < 1000; ++i) {final int finalI = i;executorService.submit(() ->System.out.println(threadLocal2.get().format(new Date(1000 * finalI))));}executorService.shutdownNow();
}
使用场景
一、每个线程需要一个独享的对象
- 通常是工具类,典型需要使用的类有 SimpleDateFormat 和 Random
- 比喻∶教材只有一本,一起做笔记有线程安全问题。复印后就没问题。
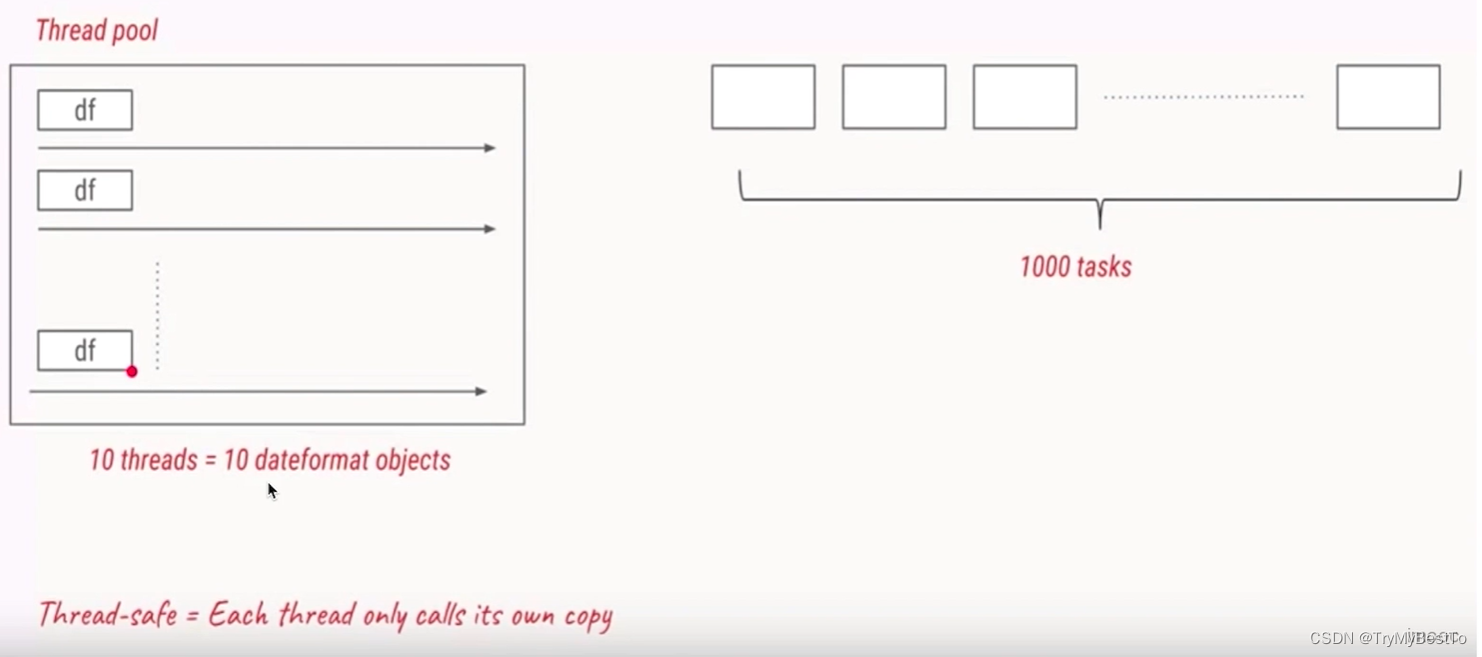
- 示例:
- 线程池有1000个线程,每个线程都要使用 SimpleDateFormat 工具类,若直接使用,则会创建 1000 个工具类,开销巨大。
- 这时可以创建一个 static 的 SimpleDateFormat 对象,让线程池的每个核心线程都使用这个静态对象,就防止了重复的创建。
- 但是,由于 SimpleDateFormat 类是线程不安全的,会出现重复的计算结果。
- 此时,可能会想到通过加锁,确实能使结果正确,但这样同一时间就只有一个线程运行了,那何必高并发呢?
- 这时,就可以使用 ThreadLocal 了,让每个核心线程内部都有自己独有的 SimpleDateFormat 对象,如图:
public static ThreadLocal<SimpleDateFormat> threadLocal2 = ThreadLocal.withInitial(() ->new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
);
@Test
void contextLoads() {ExecutorService executorService = Executors.newFixedThreadPool(10);for (int i = 0; i < 1000; ++i) {final int finalI = i;executorService.submit(() ->System.out.println(threadLocal2.get().format(new Date(1000 * finalI))));}executorService.shutdownNow();
}
二、每个线程内需要保存全局变量(例如在拦截器中获取用户信息)
- 可以让不同方法直接使用,避免参数传递的麻烦
原理
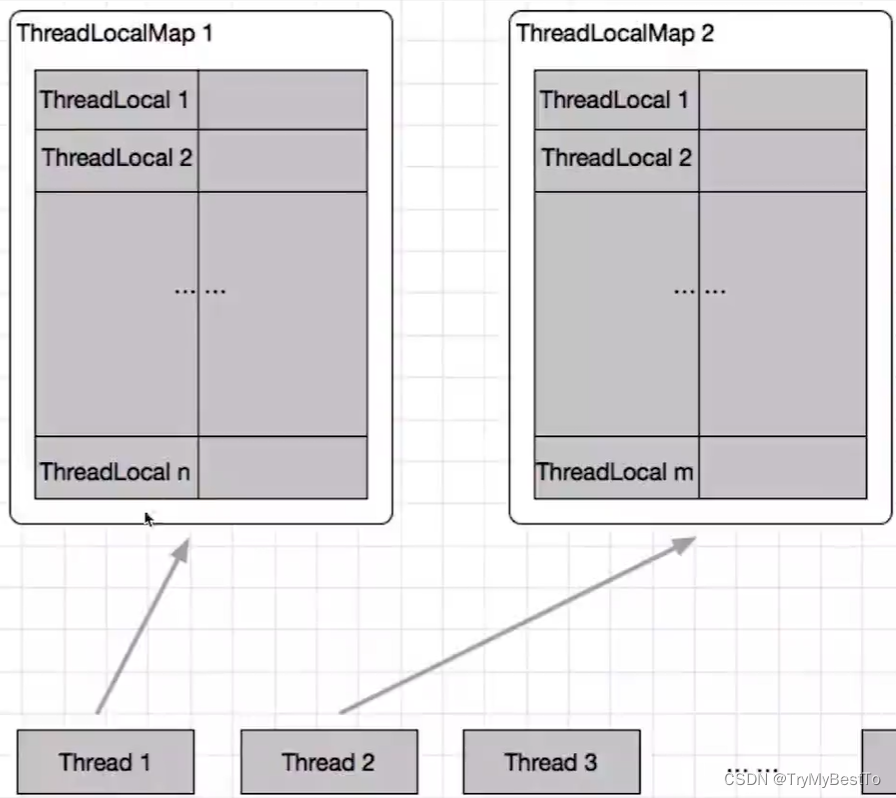
- ThreadLocal 底层是将 值 存放在线程的 ThreadLocalMap 中的。
- 通过 getMap(Thread.currentThread()) 获取 ThreadLocalMap 对象。
注意
内存泄漏:
-
内存泄露为 程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光,广义并通俗的说,就是:不再会被使用的对象或者变量占用的内存 不能被回收,就是内存泄露。
-
由于 ThreadLocalMap 继承了 WeakReference 类,属于弱引用对象。
- 弱引用,JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference 类来表示。可以在缓存中使用弱引用。
-
ThreadLocalMap 的每个 Entry 都是一个对 key 的弱引用,同时是一个对 value 的强引用。
-
正常情况下,当线程终止,保存在 ThreadLocal 里的 value 会被垃圾回收,因为没有任何强引用了但是,如果线程不终止(比如线程需要保持很久),那么 key 对应的 value 就不能被回收,因为有以下的 调用链:
- Thread —> ThreadLocalMap —>Entry ( key为null) —> Value
-
因为 value 和 Thread 之间还存在这个强引用链路,所以导致 value 无法回收,就可能会出现 OOM
- ThreadLocalMap 也有相应的处理方法(在 resize() 中):扫描 key 为 null 的Entry,并把对应的 value 设置为 null
- 但前提是得调用 map.set() 或 remove() 。
- ThreadLocalMap 也有相应的处理方法(在 resize() 中):扫描 key 为 null 的Entry,并把对应的 value 设置为 null
-
如果一个ThreadLocal 不被使用,就可能导致value的内存泄漏
如何避免内存泄露(阿里规约)
- 调用 remove 方法,就会删除对应的 Entry 对象,可以避免内存泄漏,所以使用完 ThreadLocal 之后,应该调用 remove方法。
空指针异常:
- 在创建 ThreadLcal时泛型是 包装类,如 Long,而若获取 value 时,接收返回值的对象只是基本数据类型时,有可能会拆箱错误。
- 比如,在 ThreadLocal 没有设置值时,默认是 null,而将 null 赋给 long,就会 空指针异常。
- 若使用的是包装类 Long,则不会空指针异常。
- 比如,在 ThreadLocal 没有设置值时,默认是 null,而将 null 赋给 long,就会 空指针异常。
- 因此,在接收 get() 返回值时,不建议使用 基本数据类型。