欧铂丽全屋定制价格每平米多少钱陕西优化疫情防控措施
本文参考
PyTorch深度学习项目实战100例
https://weibaohang.blog.csdn.net/article/details/127154284?spm=1001.2014.3001.5501
文章目录
- 本文参考
- 任务介绍
- 做数据的导入
- 环境介绍
- 导入必要的包
- 介绍torchnet和keras
- 做数据的导入
- 给必要的参数命名
- 加载文本数据
- 数据前处理
- 模型训练
- 验证
任务介绍
基于PyTorch使用LSTM实现新闻文本分类任务的概况如下:
任务描述:新闻文本分类是一种常见的自然语言处理任务,旨在将新闻文章分为不同的类别,如政治、体育、科技等。
方法:使用深度学习模型中的LSTM(长短时记忆网络)来处理文本序列数据。LSTM能够捕获文本中的长期依赖关系,适应不定长文本,自动提取特征,适应多类别分类,并在大型数据集上表现出色。
做数据的导入
数据+代码
https://download.csdn.net/download/weixin_55982578/88323618?spm=1001.2014.3001.5503
环境介绍
通俗的说:
直接白嫖 Google colab
优雅的说
Google Colab(Colaboratory)是一种基于云的免费Jupyter笔记本环境,具有以下优点和好处:
免费使用:Colab提供免费的GPU和TPU(Tensor Processing Unit)资源,使用户能够免费运行深度学习和机器学习任务,而无需担心硬件成本。
Google Colab(Colaboratory)是一种基于云的免费Jupyter笔记本环境,具有以下优点和好处:
免费使用:Colab提供免费的GPU和TPU(Tensor Processing Unit)资源,使用户能够免费运行深度学习和机器学习任务,而无需担心硬件成本。
导入必要的包
介绍torchnet和keras
Torchnet 是一个轻量级框架,旨在为 PyTorch 提供一些抽象和实用工具,以简化常见的深度学习研究任务。Torchnet 的设计是模块化和扩展性的,这使得研究者可以更轻松地尝试新的思路和方法。
Keras 是一个开源深度学习框架,最初由François Chollet创建并维护。它是一个高级神经网络API,旨在使深度学习模型的设计和训练变得简单而快速
!pip install torchnet
!pip install keras
import pickle
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from torch import optim
from torchnet import meter
from tqdm import tqdm```
做数据的导入
数据+代码
类别
# {0: '法治',
# 1: '国际',
# 2: '国内',
# 3: '健康',
# 4: '教育',
# 5: '经济',
# 6: '军事',
# 7: '科技',
# 8: '农经',
# 9: '三农',
# 10: '人物',
# 11: '社会',
# 12: '生活',
# 13: '书画',
# 14: '文娱'}
给必要的参数命名
# config file
# 模型输入参数,需要自己根据需要调整
num_layers = 1 # LSTM的层数
hidden_dim = 100 # LSTM中的隐层大小
epochs = 50 # 迭代次数
batch_size = 32 # 每个批次样本大小
embedding_dim = 15 # 每个字形成的嵌入向量大小
output_dim = 15 # 输出维度,因为是二分类
lr = 0.01 # 学习率
import torch# 检查是否有可用的GPU
device = torch.device('cuda')
file_path = './news.csv' # 数据路径
input_shape = 80 # 每句话的词的个数,如果不够需要使用0进行填充
加载文本数据
# 加载文本数据
def load_data(file_path, input_shape=20):df = pd.read_csv(file_path, encoding='gbk')# 标签及词汇表labels, vocabulary = list(df['label'].unique()), list(df['brief'].unique())# 构造字符级别的特征string = ''for word in vocabulary:string += word# 所有的词汇表vocabulary = set(string)# word2idx 将字映射为索引 '你':0word2idx = {word: i + 1 for i, word in enumerate(vocabulary)}with open('word2idx.pk', 'wb') as f:pickle.dump(word2idx, f)# idx2word 将索引映射为字 0:'你'idx2word = {i + 1: word for i, word in enumerate(vocabulary)}with open('idx2word.pk', 'wb') as f:pickle.dump(idx2word, f)# label2idx 将正反面映射为0和1 '法治':0label2idx = {label: i for i, label in enumerate(labels)}with open('label2idx.pk', 'wb') as f:pickle.dump(label2idx, f)# idx2label 将0和1映射为正反面 0:'法治'idx2label = {i: labels for i, labels in enumerate(labels)}with open('idx2label.pk', 'wb') as f:pickle.dump(idx2label, f)# 训练数据中所有词的个数vocab_size = len(word2idx.keys()) # 词汇表大小# 标签类别,分别为法治、健康等label_size = len(label2idx.keys()) # 标签类别数量# 序列填充,按input_shape填充,长度不足的按0补充# 将一句话映射成对应的索引 [0,24,63...]x = [[word2idx[word] for word in sent] for sent in df['brief']]# 如果长度不够input_shape,使用0进行填充x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)# 形成标签0和1y = [[label2idx[sent]] for sent in df['label']]# y = [np_utils.to_categorical(label, num_classes=label_size) for label in y]y = np.array(y)return x, y, idx2label, vocab_size, label_size, idx2word
读取数据返回参数
| 变量名 | 描述 |
|---|---|
| x | 包含了填充后的文本数据(字符索引的序列) |
| y | 包含了标签数据 |
| idx2label | 用于将模型的输出索引映射回标签 |
| vocab_size | 存储词汇表大小 |
| label_size | 存储标签类别数量 |
| idx2word | 用于将字符索引映射回字符 |
生成
| 字典名称 | 描述 |
|---|---|
| word2idx | 字符映射为索引,例如 ‘你’ 映射为 0 |
| idx2word | 索引映射回字符,例如 0 映射回 ‘你’ |
| label2idx | 标签映射为索引,例如 ‘法治’ 映射为 0 |
| idx2label | 索引映射回标签,例如 0 映射回 ‘法治’ |
代码里面提供了可视化的方法
创建LSTM 网路结构
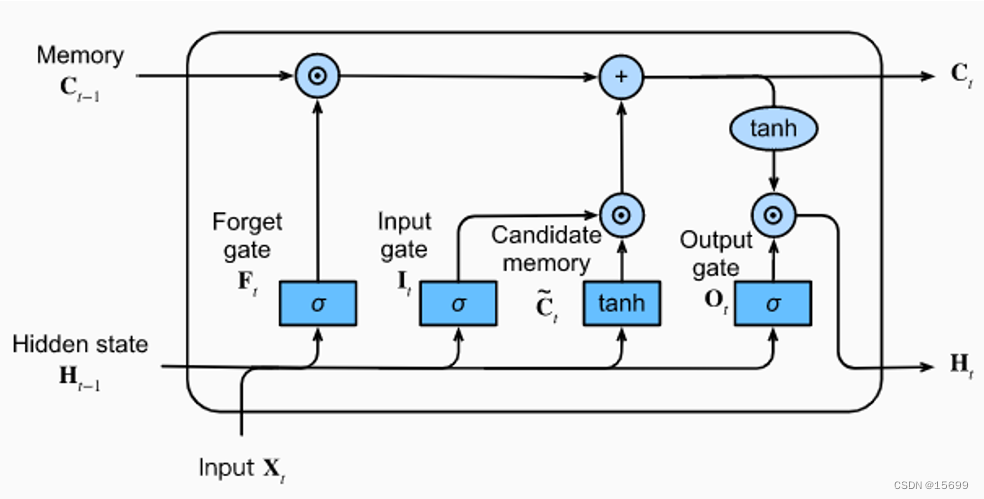
LSTM(Long Short-Term Memory)是一种循环神经网络(Recurrent Neural Network,RNN)的变种,它在处理序列数据时具有很好的性能,特别是在长序列上能够更好地捕捉长期依赖关系。下面是关于LSTM网络结构的说明:
背景:LSTM是为了解决传统RNN中的梯度消失和梯度爆炸问题而提出的。它引入了特殊的记忆单元来维护和控制信息的流动,以更好地捕捉序列数据中的长期依赖关系。
LSTM单元:LSTM网络的基本构建单元是LSTM单元。每个LSTM单元包括以下组件:
- 输入门(Input Gate):控制新信息的输入。
- 遗忘门(Forget Gate):控制过去信息的遗忘。
- 输出门(Output Gate):控制输出的生成。
- 细胞状态(Cell State):用于维护长期依赖关系的记忆。
记忆细胞:LSTM单元内部的细胞状态是其核心。它可以看作一个传送带,可以在不同时间步骤上添加或删除信息。通过输入门、遗忘门和输出门来控制信息的读取、写入和遗忘,以保持对序列中重要信息的长期记忆。
输入门:输入门决定了在当前时间步骤中,新的输入信息中哪些部分将会更新细胞状态。输入门通常由一个Sigmoid激活函数和一个tanh激活函数组成,用于产生0到1之间的权重和-1到1之间的新候选值。
遗忘门:遗忘门决定了哪些信息应该从细胞状态中丢弃。它使用Sigmoid激活函数来产生0到1之间的权重,控制细胞状态中哪些信息应该保留。
输出门:输出门决定了基于当前细胞状态和输入信息,LSTM单元应该输出什么。它使用Sigmoid激活函数来确定输出的哪些部分应该激活,并使用tanh激活函数来生成可能的输出值。
# 定义网络结构
class LSTM(nn.Module):def __init__(self, vocab_size, hidden_dim, num_layers, embedding_dim, output_dim):super(LSTM, self).__init__()self.hidden_dim = hidden_dim # 隐层大小self.num_layers = num_layers # LSTM层数# 嵌入层,会对所有词形成一个连续型嵌入向量,该向量的维度为embedding_dim# 然后利用这个向量来表示该字,而不是用索引继续表示self.embeddings = nn.Embedding(vocab_size + 1, embedding_dim)# 定义LSTM层,第一个参数为每个时间步的特征大小,这里就是每个字的维度# 第二个参数为隐层大小# 第三个参数为LSTM的层数self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers)# 利用全连接层将其映射为2维,即正反面的概率self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):# 1.首先形成嵌入向量embeds = self.embeddings(x)# 2.将嵌入向量导入到LSTM层output, (h_n, c_n) = self.lstm(embeds)# 获取输出的形状timestep, batch_size, hidden_dim = output.shape# 3.将其导入全连接层output = output.reshape(-1, hidden_dim)output = self.fc(output) # 形状为batch_size * timestep, 15# 重新调整输出的形状,使其变为 timestep x batch_size x output_dimoutput = output.reshape(timestep, batch_size, -1)# 返回最后一个时间片的输出,维度为 batch_size x output_dimreturn output[-1]数据前处理
# 1.获取训练数据
x, y, idx2label, vocab_size, label_size, idx2word = load_data(file_path, input_shape)# 2.划分训练、测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=42)# 3.将numpy转成tensor
x_train = torch.from_numpy(x_train).to(torch.int32)
y_train = torch.from_numpy(y_train).to(torch.float32)
x_test = torch.from_numpy(x_test).to(torch.int32)
y_test = torch.from_numpy(y_test).to(torch.float32)# 将训练数据和标签移到GPU上加速
x_train = x_train.to('cuda:0')
y_train = y_train.to('cuda:0')
x_test = x_test.to('cuda:0')
y_test = y_test.to('cuda:0')
使用torch中的Dataloader的方法
# 4.形成训练数据集
train_data = TensorDataset(x_train, y_train)
test_data = TensorDataset(x_test, y_test)# 5.将数据加载成迭代器
train_loader = torch.utils.data.DataLoader(train_data,batch_size,True)test_loader = torch.utils.data.DataLoader(test_data,batch_size,False)
模型训练
# 6.模型训练
model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim, num_layers=num_layers,embedding_dim=embedding_dim, output_dim=output_dim)Configimizer = optim.Adam(model.parameters(), lr=lr) # 优化器
criterion = nn.CrossEntropyLoss() # 多分类损失函数model.to(device)
loss_meter = meter.AverageValueMeter()best_acc = 0 # 保存最好准确率
best_model = None # 保存对应最好准确率的模型参数for epoch in range(epochs):model.train() # 开启训练模式epoch_acc = 0 # 每个epoch的准确率epoch_acc_count = 0 # 每个epoch训练的样本数train_count = 0 # 用于计算总的样本数,方便求准确率loss_meter.reset()train_bar = tqdm(train_loader) # 形成进度条for data in train_bar:x_train, y_train = data # 解包迭代器中的X和Yx_input = x_train.long().transpose(1, 0).contiguous()x_input = x_input.to(device)Configimizer.zero_grad()# 形成预测结果output_ = model(x_input).to(device)# 计算损失loss = criterion(output_, y_train.long().view(-1))loss.backward()Configimizer.step()loss_meter.add(loss.item())# 计算每个epoch正确的个数epoch_acc_count += (output_.argmax(axis=1) == y_train.view(-1)).sum()train_count += len(x_train)# 每个epoch对应的准确率epoch_acc = epoch_acc_count / train_count# 打印信息print("【EPOCH: 】%s" % str(epoch + 1))print("训练损失为%s" % (str(loss_meter.mean)))print("训练精度为%s" % (str(epoch_acc.item() * 100)[:5]) + '%')# 保存模型及相关信息if epoch_acc > best_acc:best_acc = epoch_accbest_model = model.state_dict()# 在训练结束保存最优的模型参数if epoch == epochs - 1:# 保存模型torch.save(best_model, './best_model.pkl')# 打印测试集精度
test_accuracy = (model(x_test.long().transpose(1, 0).contiguous()).argmax(axis=1) == y_test.view(-1)).sum() / len(y_test)
print("【训练精度为】%s" % (str(test_accuracy.item() * 100)[:5]) + '%')
验证
# 导入字典,用于形成编码
with open('word2idx.pk', 'rb') as f:word2idx = pickle.load(f)
with open('label2idx.pk', 'rb') as f:label2idx = pickle.load(f)
with open('idx2word.pk', 'rb') as f:idx2word = pickle.load(f)
with open('idx2label.pk', 'rb') as f:idx2label = pickle.load(f)try:# 数据预处理input_shape = 80 # 序列长度,就是时间步大小,也就是这里的每句话中的词的个数# 用于测试的话sent = "陈金英,一位家住浙江丽水的耄耋老人。今年这个年,陈金英过得格外舒心,因为春节前,她耗费10年,凭借自己的努力,不拖不欠,终于还清了所有欠款。"# 将对应的字转化为相应的序号x = [[word2idx[word] for word in sent]]# 如果长度不够180,使用0进行填充x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)x = torch.from_numpy(x)# 加载模型model_path = './best_model.pkl'model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim, num_layers=num_layers,embedding_dim=embedding_dim, output_dim=output_dim)model.load_state_dict(torch.load(model_path, 'cpu'))# 模型预测,注意输入的数据第一个input_shape,就是180y_pred = model(x.long().transpose(1, 0))print('输入语句: %s' % sent)print('新闻分类结果: %s' % idx2label[y_pred.argmax().item()])except KeyError as err:print("您输入的句子有汉字不在词汇表中,请重新输入!")print("不在词汇表中的单词为:%s." % err)弄成函数好调用
def classify_news_sentiment(sent):# 导入字典,用于形成编码with open('word2idx.pk', 'rb') as f:word2idx = pickle.load(f)with open('label2idx.pk', 'rb') as f:label2idx = pickle.load(f)with open('idx2word.pk', 'rb') as f:idx2word = pickle.load(f)with open('idx2label.pk', 'rb') as f:idx2label = pickle.load(f)try:# 数据预处理input_shape = 80 # 序列长度,就是时间步大小,也就是这里的每句话中的词的个数# 将对应的字转化为相应的序号x = [[word2idx[word] for word in sent]]# 如果长度不够180,使用0进行填充x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)x = torch.from_numpy(x)# 加载模型model_path = './best_model.pkl'model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim, num_layers=num_layers,embedding_dim=embedding_dim, output_dim=output_dim)model.load_state_dict(torch.load(model_path, 'cpu'))# 模型预测,注意输入的数据第一个input_shape,就是180y_pred = model(x.long().transpose(1, 0))result_label = idx2label[y_pred.argmax().item()]return result_labelexcept KeyError as err:return f"您输入的句子有汉字不在词汇表中,请重新输入!\n不在词汇表中的单词为:{err}"测试
sent = "陈金英,一位家住浙江丽水的耄耋老人。今年这个年,陈金英过得格外舒心,因为春节前,她耗费10年,凭借自己的努力,不拖不欠,终于还清了所有欠款。"
classify_news_sentiment(sent)
结果
人物