平台网站建设方案宁波网络推广公司有哪些
分布式代码的分析
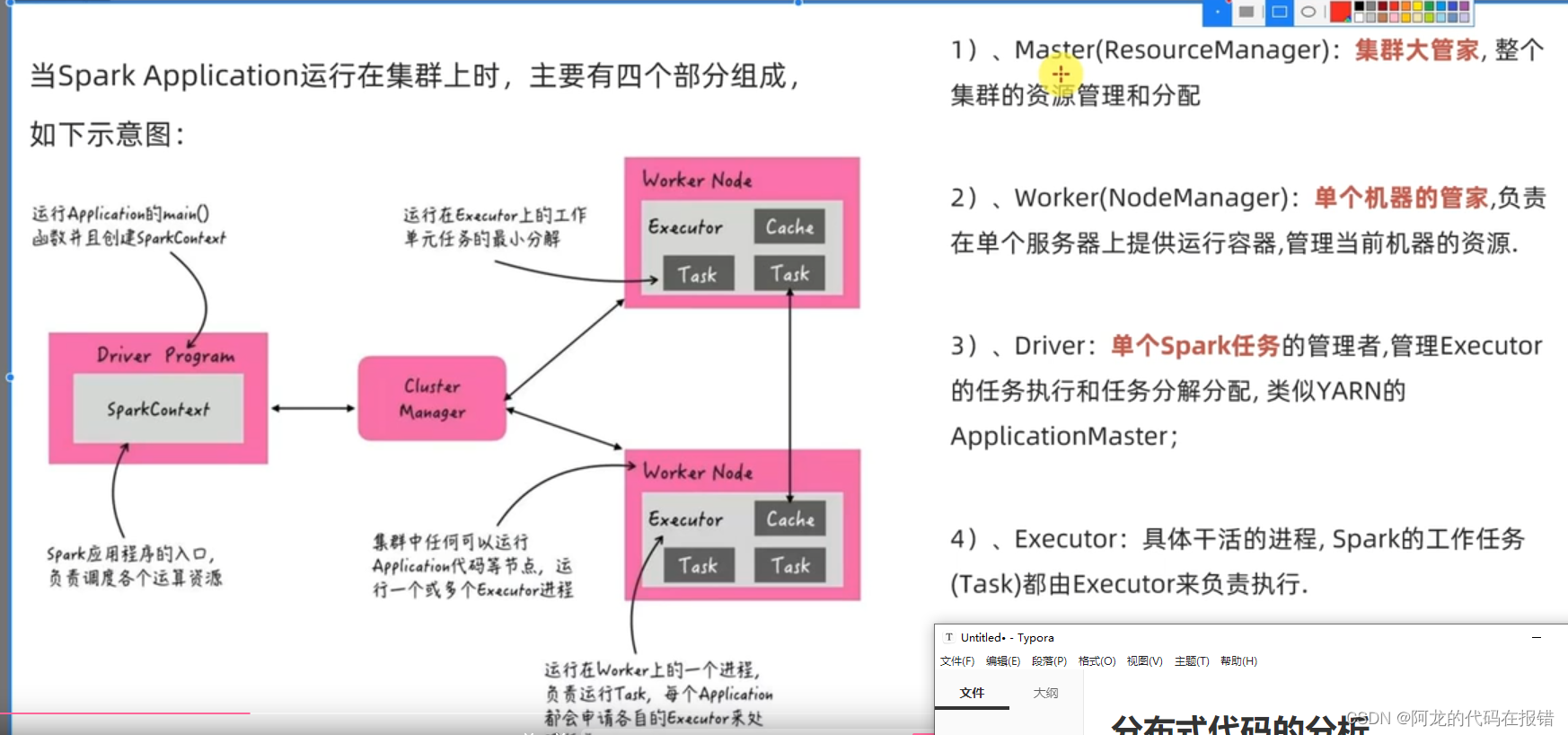
启动spark程序的代码
在yarn中启动(没有配置环境变量)
/export/server/spark/bin/spark-submit --master yarn --num-executors 6 /root/helloword.py
# 配置环境变量
spark-submit --master yarn --num-executors 6 /root/helloword.py
RDD的五大特征
1、RDD是分区的
2、计算方法都在作用在每一个分区上
3、RDD之间是有依赖关系的(RDD之间有血缘关系)
4、kv型RDD是可以有分区器的
5、RDD分区数据的读取都会接近数据所在地
RDD的创建
通过并行集合进行创建(并行化创建)
概念:并行化创建是指将本地集合-> 转向分布式RDD
这一步就是分布式的开端:本地转分布式
API:
rdd = Sparkcontext.parallelize(参数1,参数2)
参数1:集合即对象,比如list
参数2:分区数
使用案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':# 初始化执行环境,构建sparkContext对象conf = SparkConf().setAppName("TEST").setMaster("local[*]")# 通过conf创建一个SparkContext对象sc = SparkContext(conf=conf)# 通过并行化集合的方式去创建RDDrdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)分区数的参与度很小print('分区数:',rdd.getNumPartitions())print("rdd的内容:",rdd.collect())
读取外部数据源(读取文件)
读取文件创建RDD使用textfile的API
textfile 可以读取本地数据,也可以读取hdfs数据
使用方法:
sparkcontext.textFile(参数1,参数2)
# 参数1:必填,文件路径支持本地文件
# 参数2:可选,表示最小分区数量,最小分区数是参考值
wholeTextFile
读取文件API使用场景:适合读取一堆小文件
使用方法:
Sparkcontext。wholeTextfiles(参数1,参数2)# 参数1:必填,文件路径,支持本地文件,支持HDFS 也支持一些协议例如s3协议# 参数:可选,最小分区数
RDD算子
算子定义
算子:分布式集合对象的api称之为算子
方法函数:本地对象的API,叫做方法\函数
算子:分布式对象的API叫做算子
算子分类
RDD的算子分为两类:
Transformation:转换算子
Action:动作(行动)算子
Transformation(转换算子)
定义:RDD算子,返回值仍旧是一个RDD的,称之为转换算子
特性:这类算子就是 lazy 懒加载的如果没有action算子,Transformation算子是不工作的
常用的Transformation算子
map算子:
功能:map算子是将rdd的数据一条条的处理(处理的逻辑 基于map算子中接收的处理函数),并且返回新的rdd
API:
rdd.map(func)
# func: f:(T)->U
# f:表示一个函数或者方法
# (T)——》表示的是方法的定义:
# ()表示传入的参数 (T)表示 传入一个参数 ()
# T 是泛型的代称,在这里表示 任意类型
# U 也是泛型代称,在这里表示,任意类型
# -> 表示返回值
# (T)—> U 总结起来的意思是:这是一个方法,这个方法接受一个参数据传入,传入的方式类型不限,返回一个返回值,返回的类型不限
# (A)-> A 总结起来的意思是:这是一个方法,这个方法接受一个参数传入,传入的参数的类型不限,返回一个返回值,但是返回值的传入参数类型一致
map的定义方法:
# 作为算子传入函数体
rdd = sc.parallelize([1,2,3,4,5,6],3)def add(data):return data*10print(rdd.map(add).collect())reduceByKey算子
功能:针对kv型RDD自动按照key分组,然后根据自己提供的聚合逻辑完成子内数据的聚合操作
api
rdd.reduceByKey(func)
# func:(v,v)-> v
# 接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致
代码实现案例:
rdd = sc.parallelize([('a',1),('a',1),('b',1),('b',1),('a',1)])
print(rdd.reduceByKey(lambda a,b:a+b).collect())
mapValues算子
功能:针对二元元组RDD,对其内部的二元元组的value执行map操作
api:
rdd.mapValues(func)
# func:(V)->u
# 注意,传入的参数,是二元元组的value值
# 我们这个传入的方法,只对value进行处理
案例:
rdd = sc.parallelize([('a',1),('a',11),('a',6),('b',3)])
print(rdd.mapValues(lambda values :values * 10).collect())
groupBy算子
功能:将rdd的数据进行分组
API:
rdd.groupBy(func)
# func 函数
# func:(t)->k
# 函数要求传入一个参数,返回一个返回值,类型无所谓
# 这个函数是 拿到你的返回值后,将相同返回值的放入一个组中
# 分组完成后,每个组是一个二元元组,key就是返回值,所有的数据放入一个迭代器中作为value
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('groupby').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',1),('a',1),('b',1),('b',1),('b',1)])# 通过group by 对数据机型分组# group By 传入的函数意思是:这个函数确定按照谁来分组# 分组规则和SQL是一致的,相同的在一组result = rdd.groupBy(lambda t: t[0])print(result.collect())print(result.map(lambda t:(t[0] ,list(t[1]))).collect())
ilter算子
功能:过滤不想要的数据
算子案例:
from pyspark import SparkConf,SparkContext
conf = SparkConf().setAppName('filer').setMaster('local[*]')
sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4,5,6])
# 使用filer进行过滤
rdd_filer = rdd.filter(lambda x:x>1)
print(rdd_filer.collect())
distinct算子
功能:对rdd的数据进行去重,并且返回新的RDD
api:
rdd.distinct(参数1)
# 参数1:去重分区数量,一般不用
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':Conf = SparkConf().setMaster('local[*]').setAppName('distin')sc = SparkContext(conf=Conf)rdd = sc.parallelize([1,1,1,1,1,2,2,2,22,3,3,3,3,3,34])# 使用distinct对RDD数据进行去重处理rdd_distinct = rdd.distinct()print(rdd_distinct.collect())# 结果[1, 2, 34, 3, 22]
union算子
功能:将两个rdd合并成为一个rdd返回
算子特点:
1、rdd的类型不同也是可以进行合并的
2、union算子时不可以自动去重的
api:
rdd.union(other_rdd)
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('union').setMaster('local[*]')sc = SparkContext(conf=conf)rdd1 = sc.parallelize([1,2,3,4,5])rdd2 = sc.parallelize(['a','s','d','f','f'])rdd_union = rdd1.union(rdd2)print(rdd_union.collect())join算子
功能:join算子对两个RDD执行join操作(可实现SQL的内/外连接)
对于join算子来说 关联条件 是按照二元元组的key进行关联的
注意:join算子只能用于二元元组
API:
rdd.join(other_rdd)# 内连接
rdd.leftoutherjoin(other_rdd)# 左外
rdd.rightOutherjoin(other_rdd)# 右外
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setMaster('local[*]').setAppName('JOIN')sc = SparkContext(conf=conf)rdd1 = sc.parallelize([(1001,"文章"),(1002,'英文')])rdd2 = sc.parallelize([(1001,"于金陵"),(1002,'yujn=inlong'),(1003,'尽情与')])rdd_join = rdd1.join(rdd2)print(rdd_join.collect())rdd_left = rdd1.leftOuterJoin(rdd2)print(rdd_left.collect())rdd_right = rdd1.rightOuterJoin(rdd2)print(rdd_right.collect())intersection算子
功能:求2个rdd的交集,返回一个新的rdd
api:
rdd.instersection(other_rdd)
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('instersection').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4])rdd2 = sc.parallelize([1,2,3,44,550])rdd1 = rdd.intersection(rdd2)print(rdd1.collect())
glom算子
功能:将RDD的数据加上嵌套,这个嵌套按照分区来进行
当需要解嵌套是可以使用
flaimap算子进行转换
api:
rdd.glom()
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('instersection').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3)print(rdd.glom().collect())
groupByKey算子
功能:针对kv型rdd,自动按照key进行分组
api:
rdd.groupByKey()# 自动按照key分组
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('groupbykey').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',1),("a",2),('a',3),('b',1),('b',2),('b',3)])rdd_bykey = rdd.groupByKey()print(rdd_bykey.map(lambda x: (x[0],list(x[1]))).collect())
sortBy算子
功能:对rdd数据进行排序,基于你指定的排序依据
api:
rdd.sortby(func,ascending=false,numparttions=1)
# func(T)->U:告知按照rdd中的哪个数据排序比如:lambda x: x[1]表示按照rdd中的第二列元素进行排序
# ascending True 升序 false 降序
# numPartitons:用多少分区排序
算子案例:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('sortBy').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',11),('c',4),('f',3),('g',2)])rdd_sort = rdd.sortBy(lambda x: x[1], ascending=True,numPartitions=3)print(rdd_sort.collect())
sortByKey算子
功能:针对kv型RDD按照key进行排序
aip:
sortByKey(ascending= True,numPartitions=None,keyfunc=<function RDD.<lambda>)
# ascending:升序或者降序 true是升序,False是降序,默认是升序
# numPartitions:按照几个分区排序,如果全局有序,设置1
# Keyfunc :在排序前对key进行处理,语法(k)->u,一个参数传入,返回一个值
算子案例演示:
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('sortBy').setMaster('local[*]')sc = SparkContext(conf=conf)rdd = sc.parallelize([('a',11),('c',4),('f',3),('g',2),('E',1),('s',10),('Q',8)])print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())
综合案例:
import json
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':conf = SparkConf().setAppName('sortBy').setMaster('local[*]')sc = SparkContext(conf=conf)#1、 读取数据文件rdd = sc.textFile(r'C:\Users\HONOR\Desktop\测试数据\order.text')# 2、flatMap算子进行数据整理rdd_json = rdd.flatMap(lambda x: x.split('|'))# 3、通过json 库进行数据类型的转换rdd_json_j =rdd_json.map(lambda x: json.loads(x))# 4、筛选出数据中城市为北京的数据rdd_json_biejing = rdd_json_j.filter(lambda x: x['areaName'] == '北京')# 5、将城市为北京的所有商品数据类型进行的字符段进行合并并且去重rdd_l = rdd_json_biejing.map(lambda x: x['areaName']+":"+x['category']).distinct()#6、 对筛选的数据进行总结输出print(rdd_l.collect())将案例提交道YARN集群中运行
# 改动1:加入环境变量,让pycharm直接提交到yarn的时候,知道Hadoop的配置在哪,可以读取yarn的信息
import os
os.environ['HADOOP_CONF_DIR'] = '/export/server/hadoop/etc/hadoop'
# 在集群运行,本地文件就不可以用了,需要用hdfs文件
rdd = sc.textFile('hdfs://node1:8020/input/order.text')
如果在pycharm中直接提交到yarn,那么依赖的其他的python文件,可以通过设置文件属性来指定依赖代码
# 如果在代码中运行,那么依赖的文件,可以通过spark.sumbit.pyFiles属性来设置
#conf对象,可以通过setAPI 设置数据,参数1:key 参数2是value
conf.set('spark.submit.pyFiles',"defs.py")
在服务器上通过spark-submit提交到集群运行
# --py-files 可以帮你指定 你依赖的其他python代码,支持.zip(一堆),也可以单个.py文件 都行
/export/server/spark/bin/spark-submit --master yarn --py-files ./defs.[文件格式] ./mian.py