电商网站开发报告万网阿里云域名查询
任务目标
任务
1、整理火车发车信息数据,结果的表格形式为:

2、并输出最终的发车信息表
难点
1、多文件
一个文件夹,多个月的发车信息,一个excel,放一天的发车情况
2、数据表的格式特殊
如何分析表是一个难点
数据形式
图像呈现

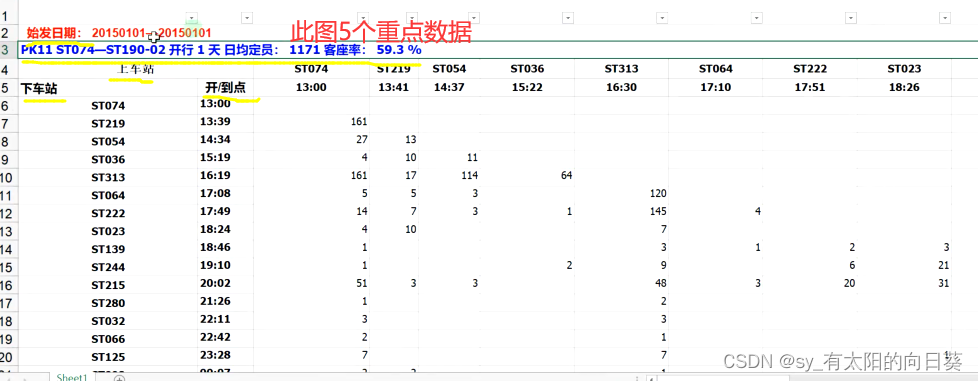


文字描述
1、一张表含多辆车次信息
2、一辆车次信息分为标题(日期、车次、定员、客座率)和表格信息部分
3、表格信息部分分为x,y轴看
横着是发车站点、发车时间、下车人数
竖着是目标站点、到达时间、上车人数
4、图标呈现下三角趋势,因为过站无上车人数
注意:
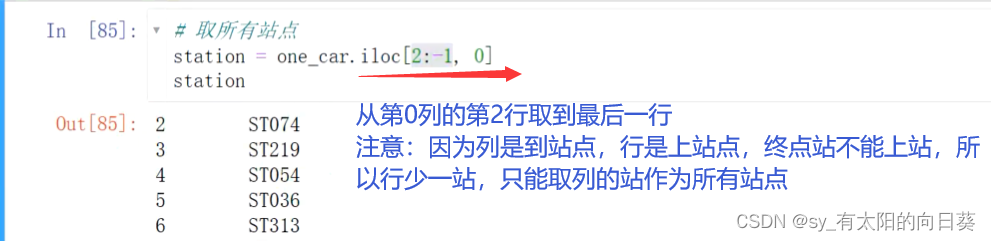
因为横着是上车站点,终点站没有人上车,所以横着的车次不包含终点站,是所有车次-1
竖着的车次包含终点站——即所有车次信息
分析步骤
1、导入数据


存在问题
与原数据不同,原数据中的表头在该表的第一列中,每个属性对应的行为空值
处理方法

处理结果

结果分析
1、38列
因为原excel表中,有车次信息到第38列,导入数据会保持表格格式完整性,所以取最大列数
不到38的列数均为空值,需要处理
2、表格信息被存放在第一行中,还需处理
3、目标需求信息只到29列的下车人数,所以需要把有效信息抠出来
语法扩展(别人的资料)
python中pandas包使用的一个header参数_header=none-CSDN博客



2、数据处理
2.1获取有效信息(扣表)
2.1.1思路分析
1、判断车次
整张表包含很多车次
要知道哪一辆车是第几行到第几行,需要拆分
(即怎么判断,eg:0-33为车1,34-45为车2,······)

2、处理表头
导入的表中有很多表头,需要处理 ,把所有车次的表头抽取出来,找共同点
都有客座率


2.1.2解决方案
1、找表头
1.1data[0]
因为数据表行列均有属性,表头均在第0列,所以先判断data[0]是第0行还是第0列

1.2找到含有“客座率”的行数

语法扩展
apply()、lambda
loc()
Pandas读取某列、某行数据——loc、iloc用法总结_pandas读取某一行的数据-CSDN博客

1.3生成由表头信息组成的表

1.4批量分割+展开表
按照空格分割后得到一个表格

split()
Python知识精解:str split()方法 - 知乎 (zhihu.com)
expand参数
pandas的分列操作str.split()_pandas数据分列-CSDN博客

2、生成除表头外的信息表
data=data[~ind]


3、生成一趟车的数据
1、根据上车站点和上车人数所在的行(用遍历匹配)
确定每一趟列车所包含的行数,再扣其中的数据
 2、找第一趟车的信息
2、找第一趟车的信息

3、重置行索引
因为之前删数据把行索引删了,出现了数据缺失,需要重置行索引
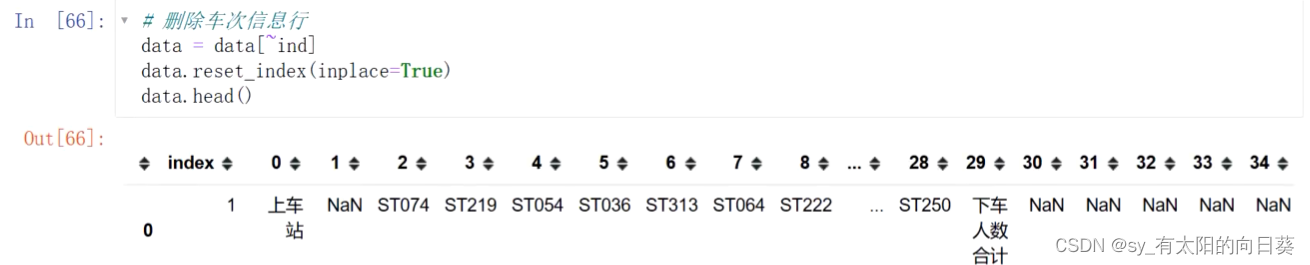

drop——删除多余的一列index
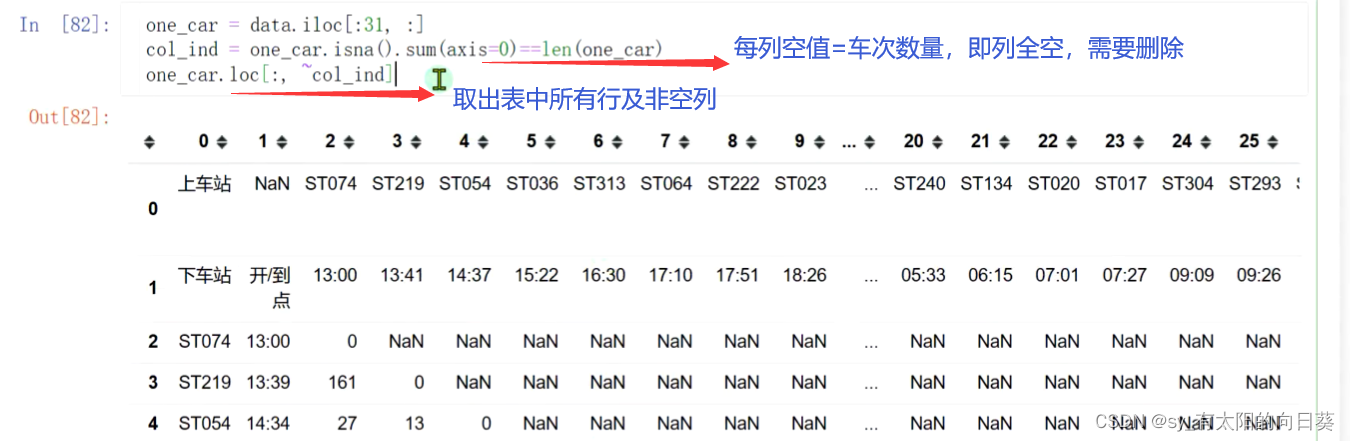
4、删除空值
重置索引后的表格为

表中30列后的值均为空值,需要删除
用空值数量进行判断,若某一列中空值数量=行数,则证明该列全为空,需要删除

5、生成完整一趟车的信息表
语法扩展
loc、iloc区别
pandas索引函数loc和iloc的区别_pandas loc与iloc区别-CSDN博客
loc基于标签索引、iloc基于位置索引
reset_index()
如何在pandas中使用set_index( )与reset_index( )设置索引 - 知乎 (zhihu.com)
3、数据分析
处理后的表

3.1取表头信息表中所需数据

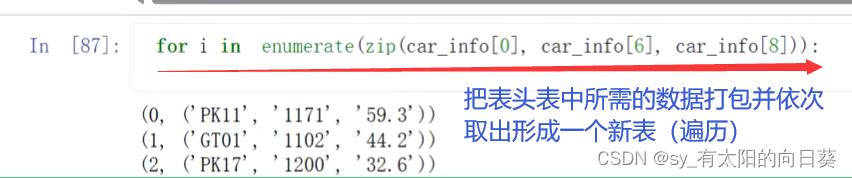
3.2把表头信息与每辆车挂钩
原数据(2个表)
表头表
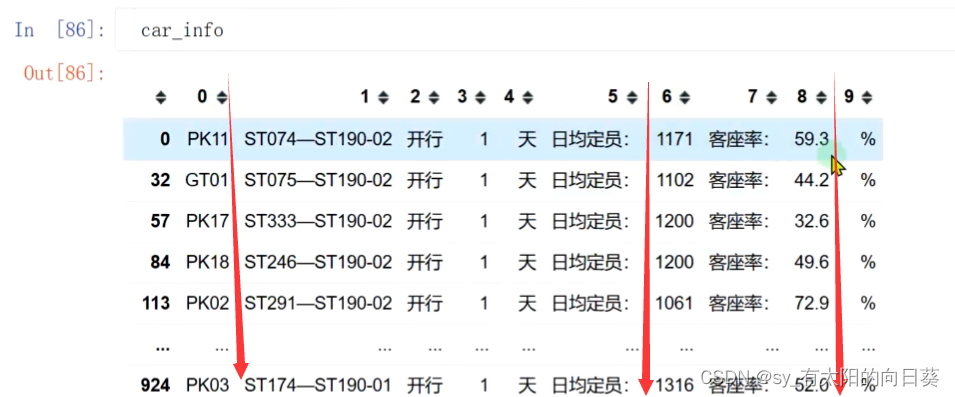
车次表

通过索引和步长取出需要的信息行
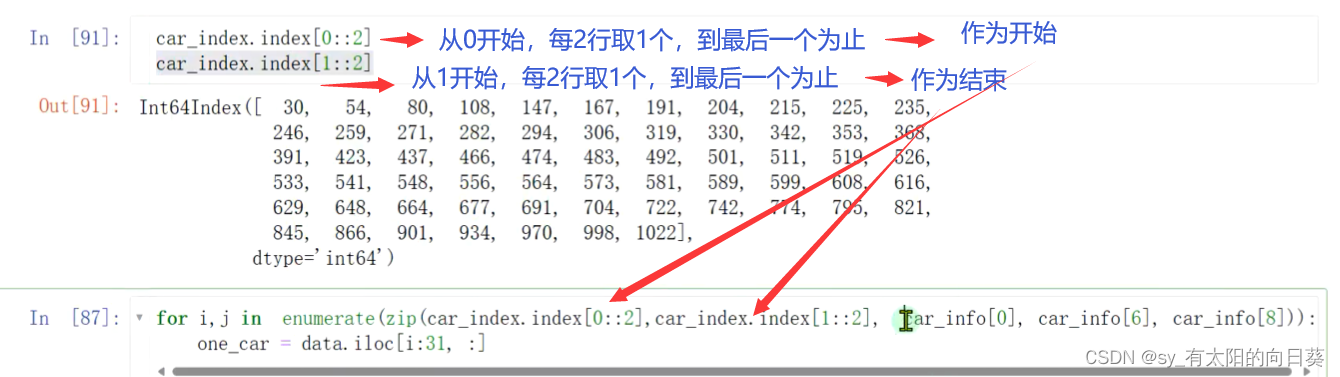
这样就匹配成功了

3.3、取所有站点
3.4循环所有站点取数据(用定位)

都用条件筛选

3.5整体操作(合并前面操作)

语法扩展
python dataframe是什么_Pandas 库之 DataFrame-CSDN博客
4、封装函数

5、数据导出


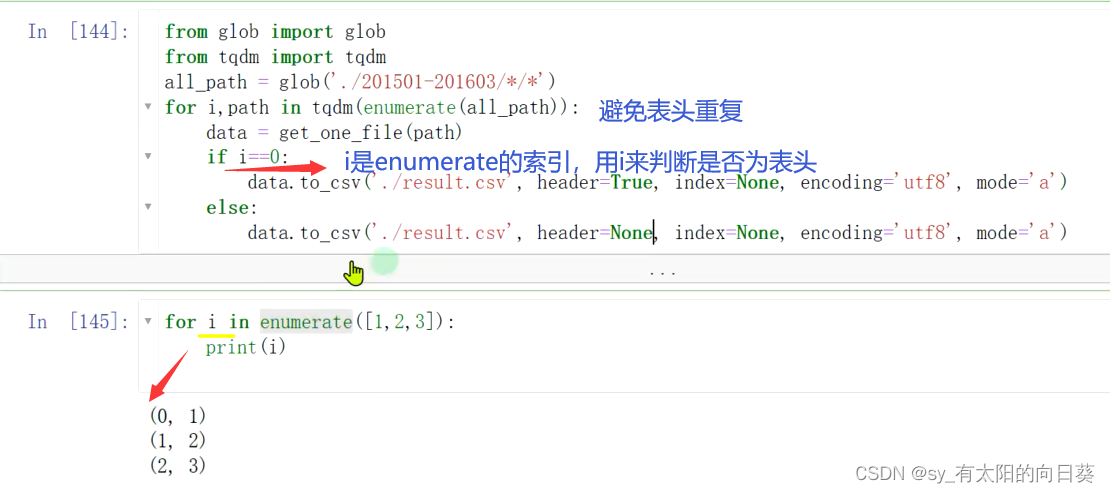
语法扩展
glob——查找文件
Python标准库glob模块详解_python glob-CSDN博客
tpdm——进度条
【python第三方库】tqdm简介_python tqdm库-CSDN博客
enumerate() 函数
Python enumerate() 函数 | 菜鸟教程
to_csv()
pandas的to_csv()使用方法_pandas to_csv-CSDN博客
总体代码
import warnings
warnings.filterwarnings('ignore')
import pandas as pdpath = './201501-201603/201501/20150101.xls'
data = pd.read_excel(path, skiprows=2, header=None)
data.head(50)# 日期
dates = path.split('/')[-1][:8]ind = data[0].apply(lambda x: '客座率' in x) # 筛选有车次信息的行数据
car_info = data.loc[ind, 0]
car_info = car_info.str.split(' ', expand=True) # 这里的得到车次、定员、客座率car_info# 删除车次信息行
data = data[~ind]
data.reset_index(inplace=True, drop=True)
data.head()## 接下来:找到某一趟车所在的小表格,思路就是找到【上车站、上车人数合计】所在的行
ind = data[0].apply(lambda x: '上车站'==x or '上车人数合计'==x)
car_index = data[ind]all_car = pd.DataFrame()
for start, end, checi, dingyuan, kezuolv in zip(car_index.index[0::2],car_index.index[1::2], car_info[0], car_info[6], car_info[8]):one_car = data.iloc[start:end+1, :] # 截取其中一趟车的数据one_car.reset_index(inplace=True, drop=True) # 重置索引col_ind = one_car.isna().sum(axis=0)==len(one_car) # 判断全为空的列one_car = one_car.loc[:, ~col_ind] # 删除空列station = one_car.iloc[2:-1, 0] # 取所有站点,在2至倒数第一行one_car_list = []for s in station: # 循环每个站点去取数据one_car_dict = {}one_car_dict['车次'] = checione_car_dict['定员'] = dingyuanone_car_dict['客座率'] = kezuolvone_car_dict['日期'] = datesone_car_dict['站点'] = sone_car_dict['进站时间'] = one_car.loc[one_car[0]==s, 1].values[0] # 进站时间one_car_dict['下车人数'] = one_car.loc[one_car[0]==s, one_car.shape[1]-1].values[0] # 下车人数try:one_car_dict['离站时间'] = one_car.loc[1,one_car.iloc[0]==s].values[0] # 离站时间one_car_dict['上车人数'] = one_car.loc[len(one_car)-1,one_car.iloc[0]==s].values[0] # 上车人数except:one_car_dict['离站时间'] = '--' # 终点站没有出站时间和人数one_car_dict['上车人数'] = '--'one_car_list.append(one_car_dict)one_car_data = pd.DataFrame(one_car_list)break#all_car = pd.concat([all_car, one_car_data])
#这一步结束就能看到处理后表的信息了one_car_datadef get_one_file(path):data = pd.read_excel(path, skiprows=2, header=None) # 读数据dates = path.split('/')[-1][:8] # 日期ind = data[0].apply(lambda x: '客座率' in x) # 筛选有车次信息的行数据car_info = data.loc[ind, 0]car_info = car_info.str.split(' ', expand=True) # 这里的得到车次、定员、客座率data = data[~ind] # 删除车次信息行data.reset_index(inplace=True, drop=True)## 接下来:找到某一趟车所在的小表格,思路就是找到【上车站、上车人数合计】所在的行ind = data[0].apply(lambda x: '上车站'==x or '上车人数合计'==x)car_index = data[ind]all_car = pd.DataFrame()for start, end, checi, dingyuan, kezuolv in zip(car_index.index[0::2],car_index.index[1::2], car_info[0], car_info[6], car_info[8]):one_car = data.iloc[start:end+1, :] # 截取其中一趟车的数据one_car.reset_index(inplace=True, drop=True) # 重置索引col_ind = one_car.isna().sum(axis=0)==len(one_car) # 判断全为空的列one_car = one_car.loc[:, ~col_ind] # 删除空列station = one_car.iloc[2:-1, 0] # 取所有站点,在2至倒数第一行one_car_list = []for s in station: # 循环每个站点去取数据one_car_dict = {}one_car_dict['车次'] = checione_car_dict['定员'] = dingyuanone_car_dict['客座率'] = kezuolvone_car_dict['日期'] = datesone_car_dict['站点'] = sone_car_dict['进站时间'] = one_car.loc[one_car[0]==s, 1].values[0] # 进站时间one_car_dict['下车人数'] = one_car.loc[one_car[0]==s, one_car.shape[1]-1].values[0] # 下车人数try:one_car_dict['离站时间'] = one_car.loc[1,one_car.iloc[0]==s].values[0] # 离站时间one_car_dict['上车人数'] = one_car.loc[len(one_car)-1,one_car.iloc[0]==s].values[0] # 上车人数except:one_car_dict['离站时间'] = '--' # 终点站没有出站时间和人数one_car_dict['上车人数'] = '--'one_car_list.append(one_car_dict)one_car_data = pd.DataFrame(one_car_list)all_car = pd.concat([all_car, one_car_data])return all_carfrom glob import glob
from tqdm import tqdm
all_path = glob('./201501-201603/*/*')
for i,path in tqdm(enumerate(all_path)):data = get_one_file(path)if i==0:data.to_csv('./result.csv', header=True, index=None, encoding='utf8', mode='a')else:data.to_csv('./result.csv', header=None, index=None, encoding='utf8', mode='a')