安徽盛绿建设网站网站优化怎么操作
前言
数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。
我很负责的告诉大家,该问题无论在面试,还是工作中遇到的概率非常大,所以非常有必要跟大家一起探讨一下。
今天这篇文章我会从浅入深,跟大家一起聊聊,数据库和缓存双写数据一致性问题常见的解决方案,这些方案中可能存在的坑,以及最优方案是什么。
1、 常见方案
通常情况下,我们使用缓存的主要目的是为了提升查询的性能。大多数情况下,我们是这样使用缓存的:
用户请求过来之后,先查缓存有没有数据,如果有则直接返回。
如果缓存没数据,再继续查数据库。
如果数据库有数据,则将查询出来的数据,放入缓存中,然后返回该数据。
如果数据库也没数据,则直接返回空。
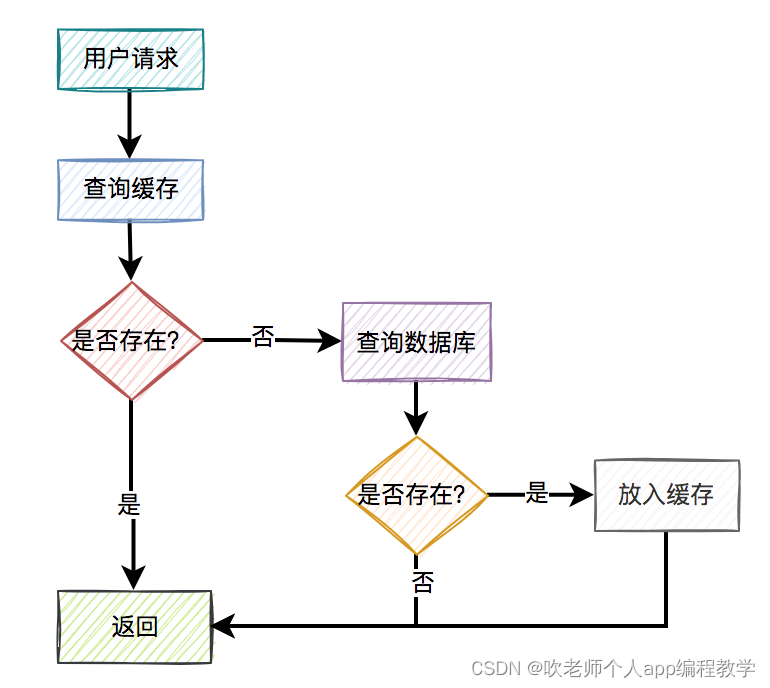
这是缓存非常常见的用法。一眼看上去,好像没有啥问题。
但你忽略了一个非常重要的细节:如果数据库中的某条数据,放入缓存之后,又立马被更新了,那么该如何更新缓存呢?
不更新缓存行不行?
答:当然不行,如果不更新缓存,在很长的一段时间内(决定于缓存的过期时间),用户请求从缓存中获取到的都可能是旧值,而非数据库的最新值。这不是有数据不一致的问题?
那么,我们该如何更新缓存呢?
目前有以下4种方案:
先写缓存,再写数据库
先写数据库,再写缓存
先删缓存,再写数据库
先写数据库,再删缓存
接下来,我们详细说说这4种方案。
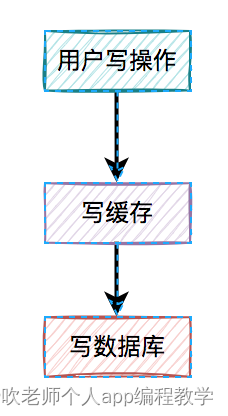
2、先写缓存,再写数据库
对于更新缓存的方案,很多人第一个想到的可能是在写操作中直接更新缓存(写缓存),更直接明了。
那么,问题来了:在写操作中,到底是先写缓存,还是先写数据库呢?
我们在这里先聊聊先写缓存,再写数据库的情况,因为它的问题最严重。
某一个用户的每一次写操作,如果刚写完缓存,突然网络出现了异常,导致写数据库失败了。其结果是缓存更新成了最新数据,但数据库没有,这样缓存中的数据不就变成脏数据了?如果此时该用户的查询请求,正好读取到该数据,就会出现问题,因为该数据在数据库中根本不存在,这个问题非常严重。
我们都知道,缓存的主要目的是把数据库的数据临时保存在内存,便于后续的查询,提升查询速度。
但如果某条数据,在数据库中都不存在,你缓存这种“假数据”又有啥意义呢?
因此,先写缓存,再写数据库的方案是不可取的,在实际工作中用得不多。
3、先写数据库,再写缓存
既然上面的方案行不通,接下来,聊聊先写数据库,再写缓存的方案,该方案在低并发编程中有人在用(我猜的)。
用户的写操作,先写数据库,再写缓存,可以避免之前“假数据”的问题。但它却带来了新的问题。
什么问题呢?
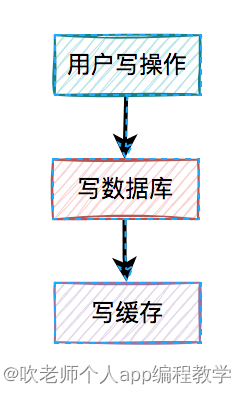
3.1 写缓存失败了
如果把写数据库和写缓存操作,放在同一个事务当中,当写缓存失败了,我们可以把写入数据库的数据进行回滚。
如果是并发量比较小,对接口性能要求不太高的系统,可以这么玩。
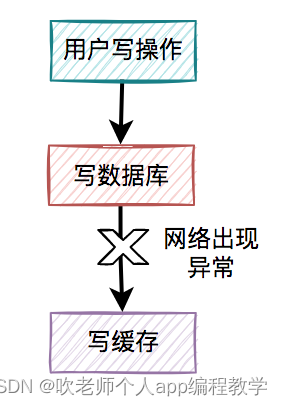
但如果在高并发的业务场景中,写数据库和写缓存,都属于远程操作。为了防止出现大事务,造成的死锁问题,通常建议写数据库和写缓存不要放在同一个事务中。
也就是说在该方案中,如果写数据库成功了,但写缓存失败了,数据库中已写入的数据不会回滚。
这就会出现:数据库是新数据,而缓存是旧数据,两边数据不一致的情况。
3.2 高并发下的问题
假设在高并发的场景中,针对同一个用户的同一条数据,有两个写数据请求:a和b,它们同时请求到业务系统。
其中请求a获取的是旧数据,而请求b获取的是新数据,如下图所示:
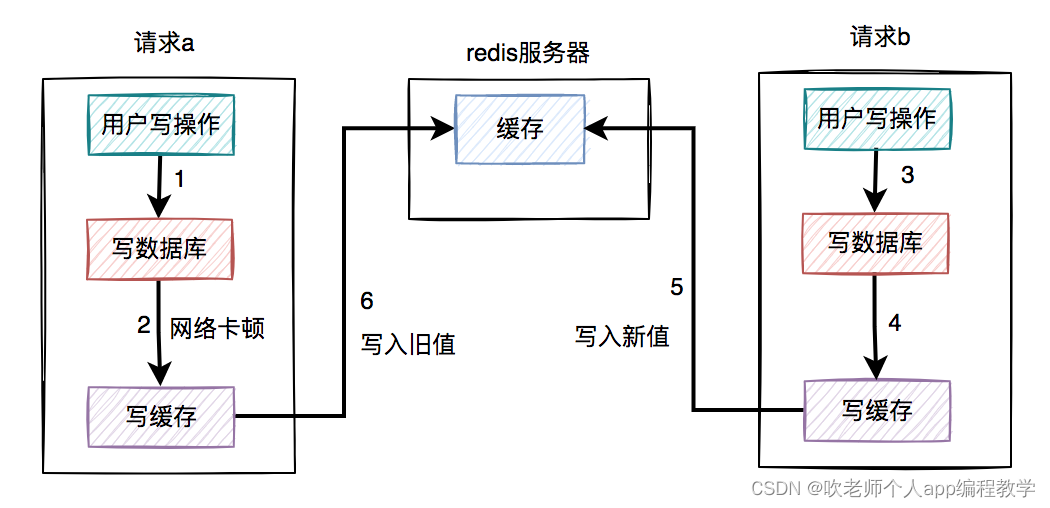
请求a先过来,刚写完了数据库。但由于网络原因,卡顿了一下,还没来得及写缓存。
这时候请求b过来了,先写了数据库。
接下来,请求b顺利写了缓存。
此时,请求a卡顿结束,也写了缓存。
很显然,在这个过程当中,请求b在缓存中的新数据,被请求a的旧数据覆盖了。
也就是说:在高并发场景中,如果多个线程同时执行先写数据库,再写缓存的操作,可能会出现数据库是新值,而缓存中是旧值,两边数据不一致的情况。
3.3、浪费系统资源
该方案还有一个比较大的问题就是:每个写操作,写完数据库,会马上写缓存,比较浪费系统资源。
为什么这么说呢?
你可以试想一下,如果写的缓存,并不是简单的数据内容,而是要经过非常复杂的计算得出的最终结果。这样每写一次缓存,都需要经过一次非常复杂的计算,不是非常浪费系统资源吗?
尤其是cpu和内存资源。
还有些业务场景比较特殊:写多读少。
如果在这类业务场景中,每个用的写操作,都需要写一次缓存,有点得不偿失。
由此可见,在高并发的场景中,先写数据库,再写缓存,这套方案问题挺多的,也不太建议使用。
如果你已经用了,赶紧看看踩坑了没?