郑州做网站哪个公司好代运营一家店铺多少钱
1.单节点训练
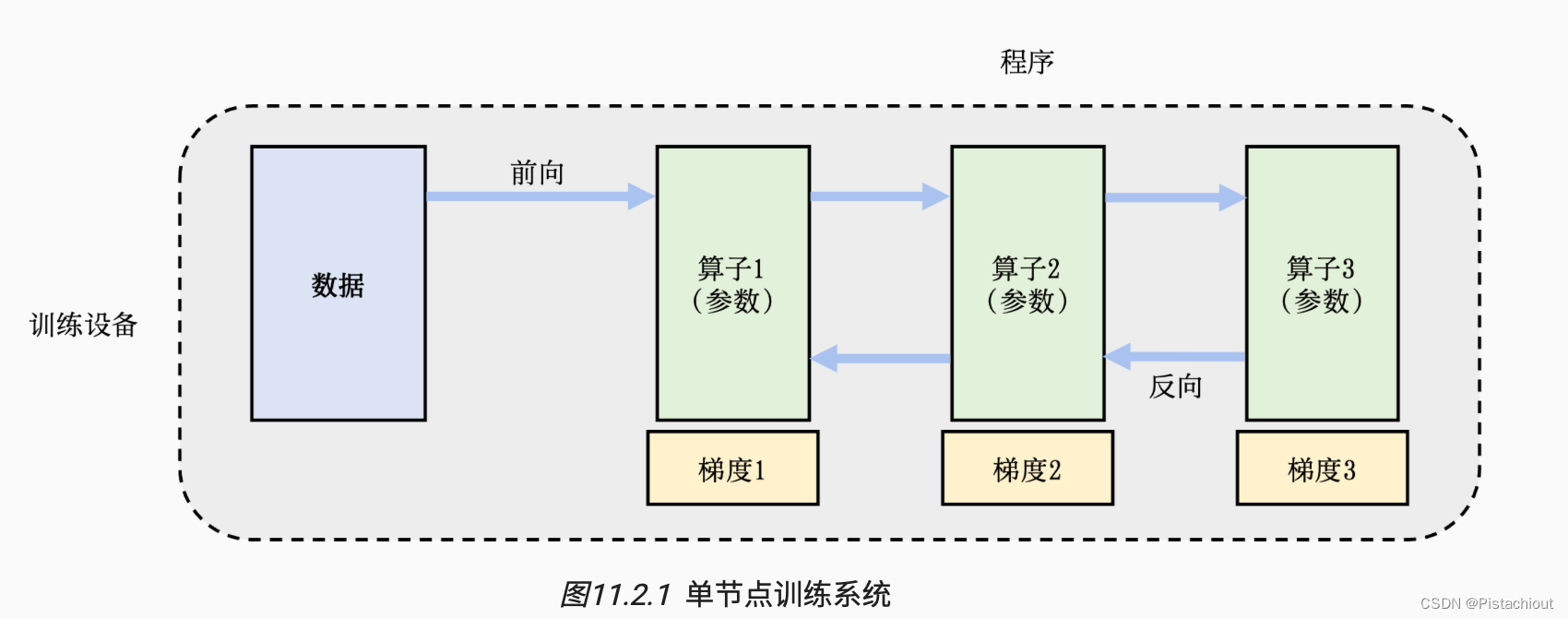
单节点训练也会转换为等价的并行训练,如在GPU内同一wrap内的32个Thread执行同一指令,但处理不同的数据。
训练程序往往实现了一个多层神经网络的执行过程。该神经网络的执行由一个计算图(Computational Graph)表示。这个图有多个相互连接的算子(Operator),每个算子会拥有计算参数。每个算子往往会实现一个神经网络层(Neural Network Layer),而参数则代表了这个层在训练中所更新的的权重(Weights)。
为了更新参数,计算图的执行分为前向计算和反向计算两个阶段。前向计算的第一步会将数据读入第一个算子,该算子会根据当前的参数,计算出给下一个算子的数据。反向计算中,每个算子依次计算出梯度,并利用梯度更新本地的参数。反向计算的结束也标志本次数据小批次的结束,系统随之读取下一个数据小批次,继续更新模型。
2.分布式训练
2.1 数据并行DP
解决单卡算力不足
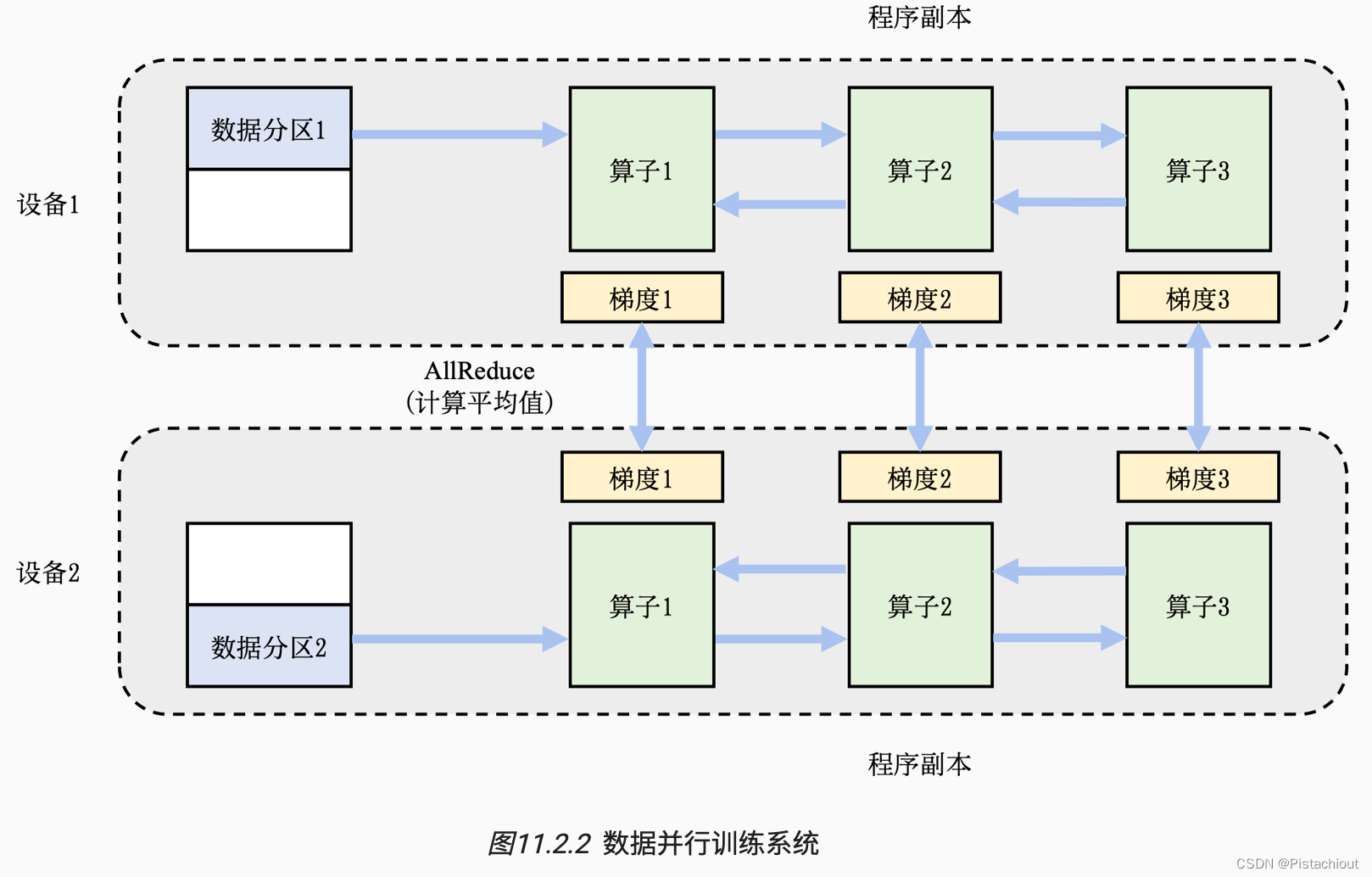
数据进行分区,共享训练程序,反向计算时不同设备根据各自的训练样本生成局部梯度Gi,之后不同设备对应的局部梯度进行聚合得到平均梯度,用平均梯度修正模型参数,完成小批次的训练。这个聚合的过程往往由集合通信的AllReduce操作完成。
2.2 模型并行MP
解决单卡内存不足
2.2.1 算子内并行 、张量并行TP
场景:假设某个算子具有𝑃个参数,而系统拥有𝑁个设备,那么可以将𝑃个参数平均分配给𝑁个设备(每个设备分配𝑃/𝑁个参数),从而让每个设备负责更少的计算量,能够在内存容量的限制下完成前向计算和反向计算。也被称为算子内并行(Intra-operator Parallelism)。
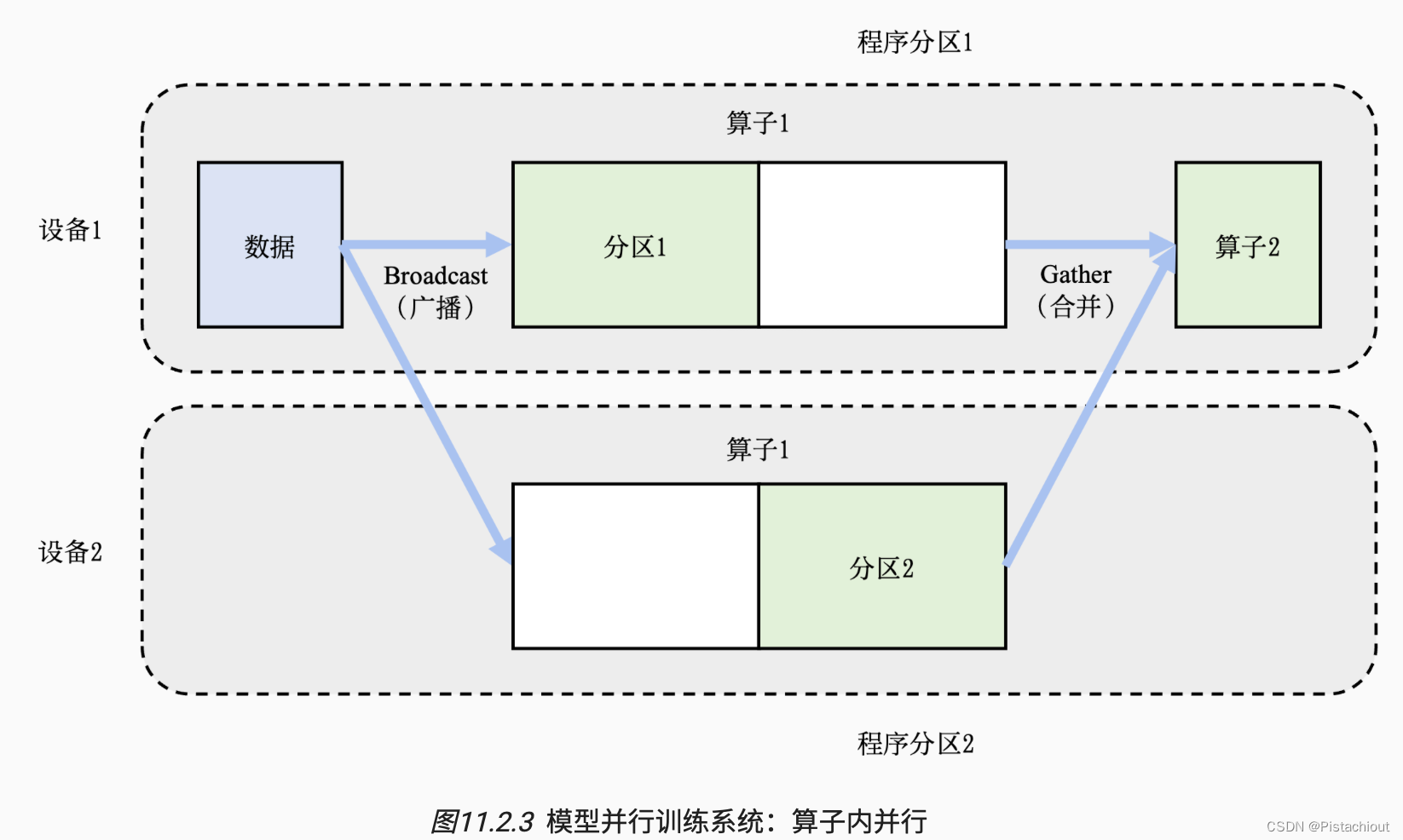
将算子1的参数平均分区,设备1和设备2各负责其中部分算子1的参数。
2.2.2 算子间并行
场景:模型的总内存需求超过了单设备的内存容量。在这种场景下,假设总共有𝑁个算子和𝑀个设备,可以将算子平摊给这𝑀个设备,让每个设备仅需负责𝑁/𝑀个算子的前向和反向计算,降低设备的内存开销。这种并行方式是模型并行的另一种应用,被称为算子间并行(Inter-operator Parallelism)
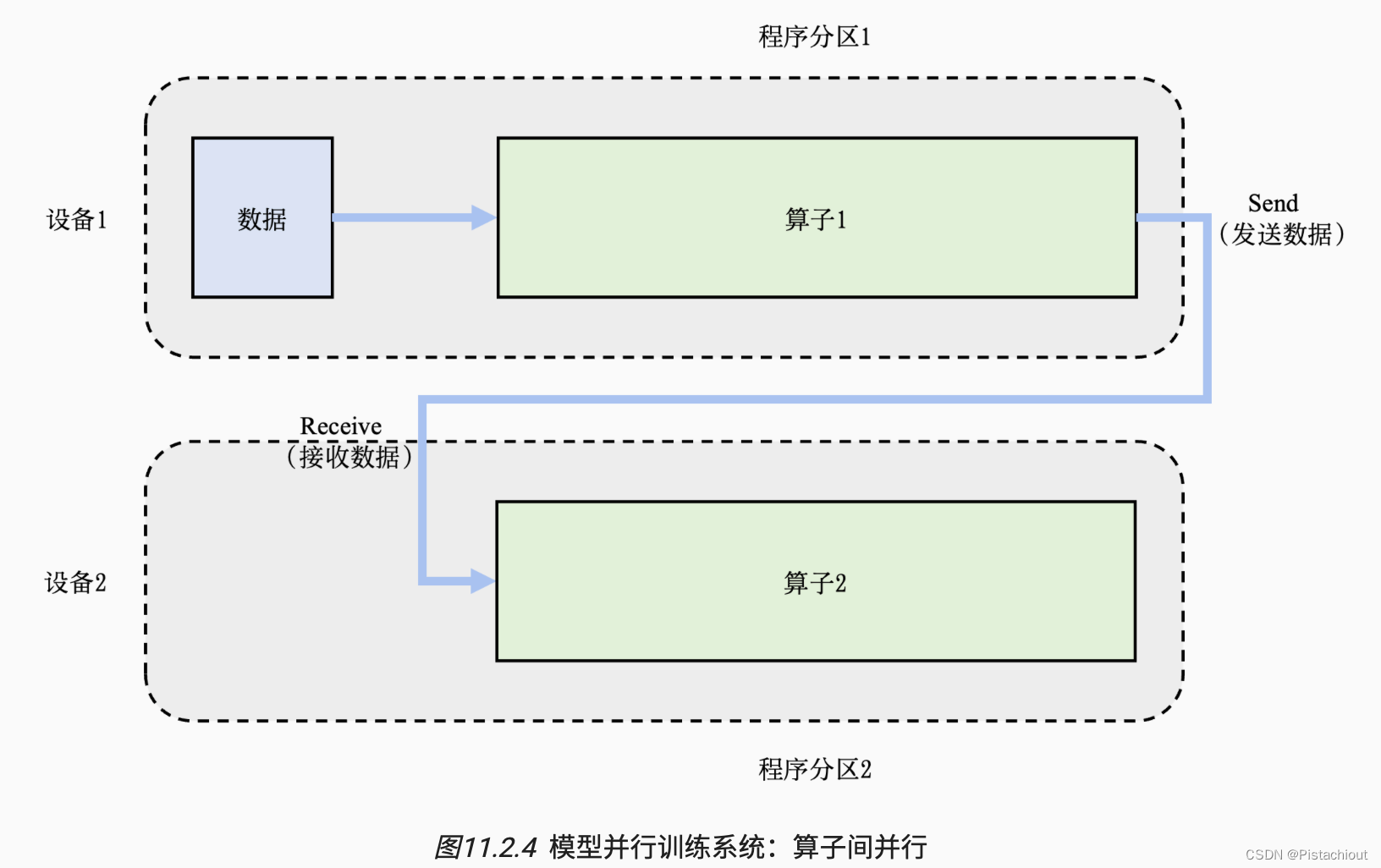
将算子进行分开,设备1和设备2各负责一个算子。
2.3 流水线并行PP
2.3.1 并行气泡
大型模型并行采用算子内并行+算子间并行解决单设备内存不足,这种情况下,计算中的下游设备(Downstream Device)需要长期持续处于空闲状态,等待上游设备(Upstream Device)的计算完成,才可以开始计算,这极大降低了设备的平均使用率。这种现象称为模型并行气泡。因此采用流水线并行减少气泡(可以类比CPU设计中的指令流水线,提升设备使用率)。
2.3.2 微批次
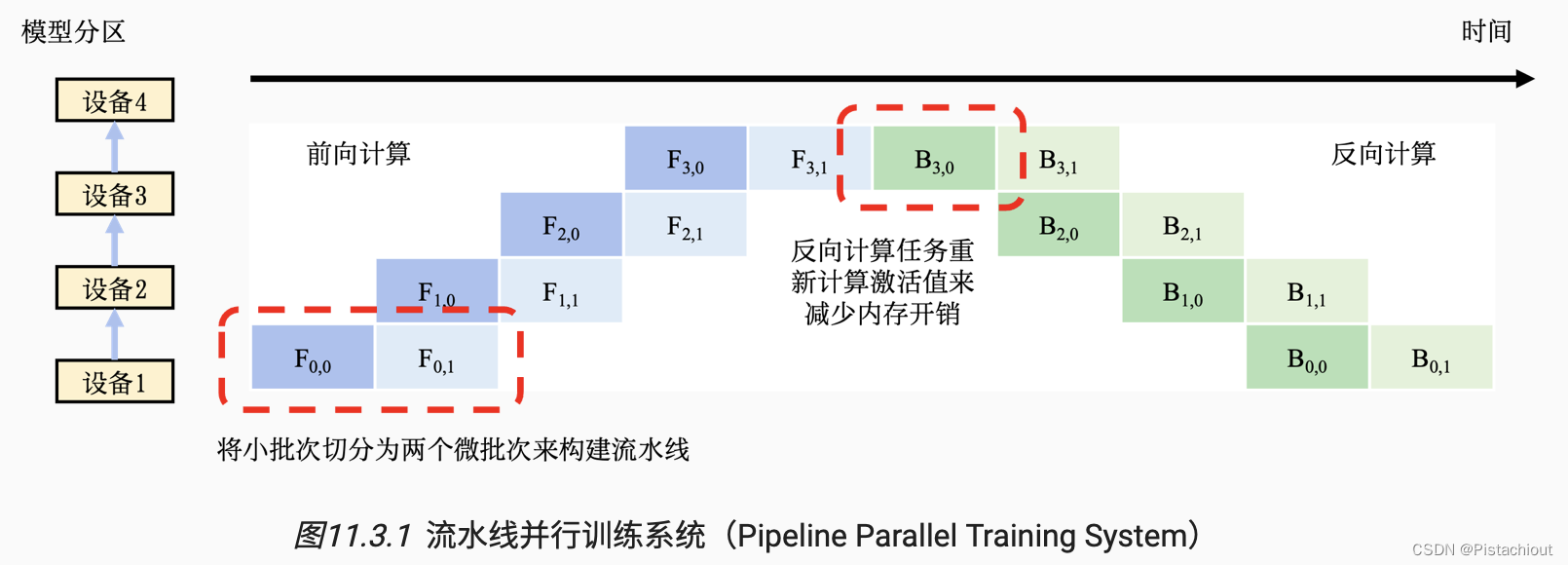
将训练数据中的每一个小批次划分为多个微批次(Micro-Batch)。假设一个小批次有𝐷个训练样本,将其划分为𝑀个微批次,那么一个微批次就有𝐷/𝑀个数据样本。每个微批次依次进入训练系统,完成前向计算和反向计算,计算出梯度。每个微批次对应的梯度将会缓存,等到全部微批次完成,缓存的梯度会被加和,算出平均梯度(等同于整个小批次的梯度),完成模型参数的更新。
2.3.3流水线并行优化-1F1B模式
1F1B(One Forward pass followed by One Backward pass)模式,一种前向计算和反向计算交叉进行的方式。
如上图为字节万卡集群论文中的1F1B模式
在流水线并行中,MegaScale使用交错1F1B调度方法,以实现通信的重叠。在热身阶段,前向传递仅依赖于其先前的接收。我们解耦了通常一起实现的发送和接收,通过打破这种依赖关系,使得发送操作能够与计算重叠。在张量/序列并行中,介绍了融合通信和计算等优化策略,以及将GEMM内核分成小块并与通信进行流水线执行。
2.3.4 流水线并行性能
在使用流水线训练系统中,时常需要调试微批次的大小,从而达到最优的系统性能。当设备完成前向计算后,必须等到全部反向计算开始,在此期间设备会处于空闲状态。在 图11.3.1中,可以看到设备1在完成两个前向计算任务后,要等很长时间才能开始两个反向计算任务。这其中的等待时间即被称为流水线气泡(Pipeline Bubble)。为了减少设备的等待时间,一种常见的做法是尽可能地增加微批次的数量,从而让反向计算尽可能早开始。然而,使用非常小的微批次,可能会造成微批次中的训练样本不足,从而无法充分的利用起来硬件加速器中的海量计算核心。因此最优的微批次数量由多种因素(如流水线深度、微批次大小和加速器计算核心数量等)共同决定。
2.4 混合并行
2.4.1 数据并行+算子间并行

2.4.2 3D并行DP+PP+TP
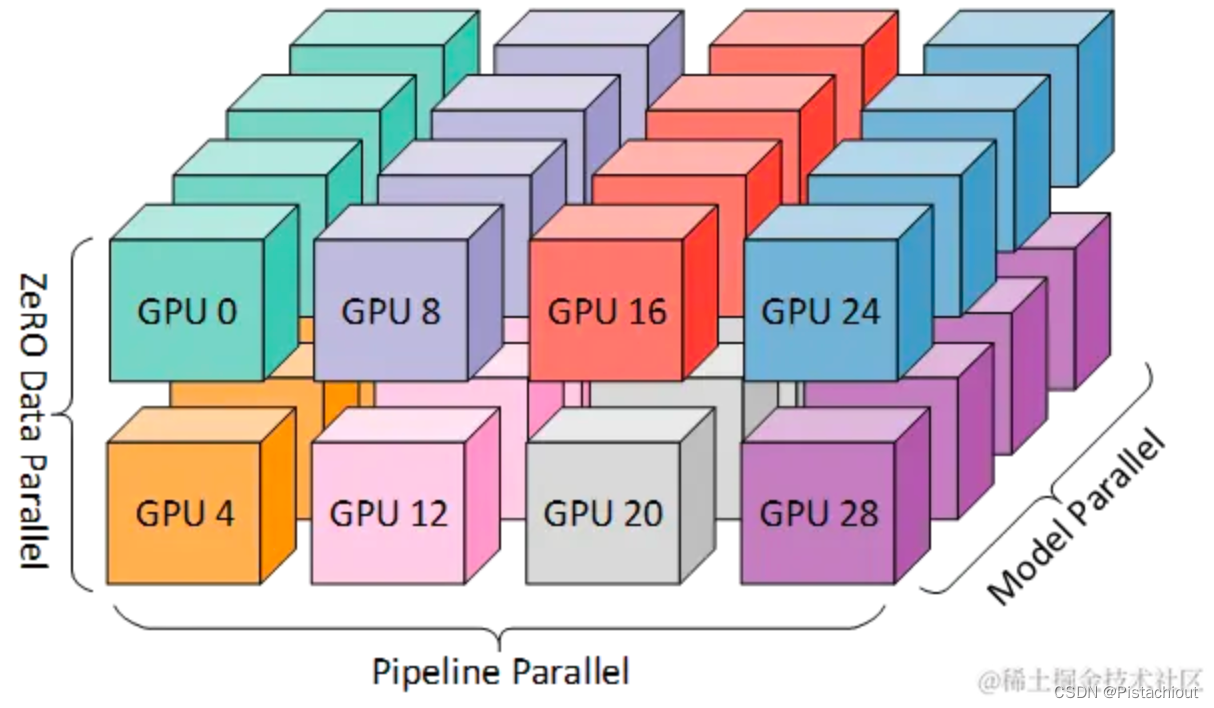
一般业界将数据并行+模型张量并行+流水线并行混合成为3D并行。由于每个维度至少需要 2 个 GPU,因此在这里你至少需要 8 个 GPU 才能实现完整的 3D 并行。
如英伟达开源的Megatron-LM与字节的MegaScale都是3D并行
参考:
https://openmlsys.github.io/chapter_distributed_training/index.html
https://juejin.cn/post/7277799192966578176