请列出页面上影响网站排名的因素模板建网站价格
背景
Metrics SDK 是与字节内场时序数据库 ByteTSD 配套的用户指标打点 SDK,在字节内数十万服务中集成,应用广泛,因此 SDK 的性能优化是个重要和持续性的话题。本文主要以 Go Metrics SDK 为例,讲述对打点 API 的 hot-path 优化的实践。
用户在使用 SDK API 进行打点时,需要传入指标对应的 Tag:
tags := []m.T{{Name: "foo", Value: "a"}, {Name: "bar", Value: "b"}}
metric.WithTags(tags...).Emit(m.Incr(1))SDK 内部需要对用户传入的 Tag Value 的合法性进行校验,IsValidTagValue,是 SDK 中对 Tag Value 进行字符合法性校验的 util 函数,在对内部一些用户的业务使用 pprof 拉取 profile 时,发现这两个函数的 CPU 消耗占整个打点 API 过程的10%~20%,由于该函数发生在打点 API 的 hot-path 上,因此有必要对其进行进一步优化。
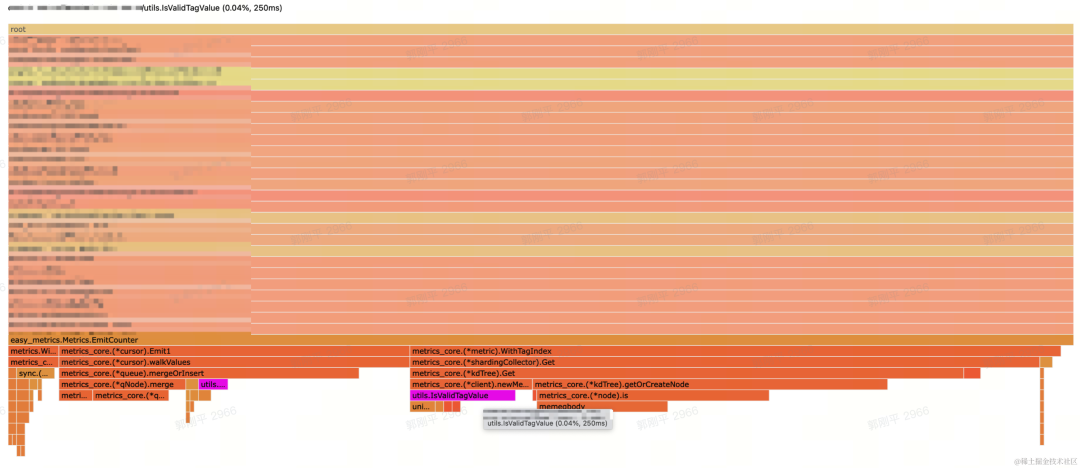
分析
当前实现
我们先看一下 IsValidTagValue 函数内部的实现方式,是否有可优化的点。当前的实现,对于通过 API 传入的每一个Tag Value,会进行以下操作来判断其合法性:
先判断是否是在 Letter、Number 的范围内,是则直接通过;
存储所有允许的特殊字符白名单,遍历 Tag Value 对比其每个字符是否在白名单内。
var (// these runes are valid in tag valueswhiteListRunes = []rune{'_', '-', '.', '%', ':', ' ', '[', ']', ',', '%','/', ':', ';', '<', '=', '>', '@', '~'}
)func IsValidTagValue(s string) bool {if len(s) == 0 || len(s) > maxTagLen {return false}for i, r := range s {if r < minValidChar || r > maxValidChar {return false}if unicode.IsLetter(r) || unicode.IsNumber(r) || isRuneInWhiteList(r) {continue}return false}return true
}该实现的时间复杂度简单分析如下:
对于由 Letter、Number 这样的合法字符构成的字符串(大部分场景),其时间复杂度是:
对于全由特殊字符构成的字符串,其时间复杂度是:
整个字符串的时间复杂度将介于 到之间
问题点
可以看到,从当前实现看,一个主要影响性能的点是白名单列表的循环遍历对比操作,我们需要考虑可能的优化方式来降低这个操作的时间复杂度。
优化
优化一:使用 Lookup Table,空间换时间
Metrics SDK 所有允许的合法的字符,实际上是 ASCII 的一个子集,也就是说其所有可能的字符最多只有128个,因此,我们可以通过空间换时间的方式,将对白名单的 O(n) 遍历操作转换为 O(1) 的查表操作:
提前对这128个字符建立一个包含128个成员的数组,在每一个 offset 上标记对应字符是否合法(合法则标记为
1),这样就建立了一个快速的 lookup table对于要校验的每一个字符,只要将其转化为数组 offset,直接取数组成员值判断是否为
1即可

table := [128]uint8{...}
// fill flags
for i := 0; i < 128; i++ {if unicode.IsNumber(rune(i)) || unicode.IsLetter(rune(i)) || isRuneInWhiteList(rune(i)) {table[i] = 1}
}str := "hello"for _, char := range []byte(str) {if r > maxValidChar {return false}if table[char] != 1 {return false}
}
return trueBenchmark
goos: linux
goarch: amd64
pkg: code.byted.org/gopkg/metrics_core/utils
cpu: Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
BenchmarkLookupAlgoValid
BenchmarkLookupAlgoValid/baseline
BenchmarkLookupAlgoValid/baseline-8 2839345 478.9 ns/op
BenchmarkLookupAlgoValid/lookup-arraytable
BenchmarkLookupAlgoValid/lookup-arraytable-8 6673456 167.8 ns/op可以看到,速度提升60%
优化二:使用 SIMD,提升并行度
基于 Lookup Table 的校验方式,将字符串校验的时间复杂度稳定在了, 但有没有可能进一步减少对字符串每一个字符的遍历次数,比如一次校验16个字符?
我们知道,SIMD 指令是循环展开优化的常用思路,那么这里是否可以引入 SIMD 来进一步提升运算并行度和效率?
答案是肯定的,以 intel x86 架构为例,参考其 Intrinsics Guide,在不同的 SIMD 指令集上提供了多个可以实现在不同大小的 lookup table 中查找数据的指令,这些指令可以作为我们加速方案的基础:

注:可以通过
cat /proc/cpuinfo命令来查看机器支持的simd指令集
鉴于 vpermi2b 指令的支持目前不是很普遍的原因,我们考虑使用 pshufb 来实现一个 SIMD 版本,但我们的Lookup Table 需要调整下,因为:
虽然我们基于 bitmap 实现的 Lookup Table 是 128 bits,刚好可以填充 128 bits 的寄存器
但 pshufb 是按字节进行 lookup 的,128 bits 的寄存器支持16字节的 lookup
因此,我们需要将 bitmap lookup table 做一次升维,变成一个16*8 bits 的二维 lookup table,做两次递进的行、列 lookup 完成查找,基于该思路,可以实现一次校验16个字符,大大提升并行度。
整体方案
该方案主要参考这篇文章:SIMDized check which bytes are in a set(http://0x80.pl/articles/simd-byte-lookup.html)
构建 bitmap table
对于一个 ASCII 字符,我们用其低 4bits 作为 lookup table 的 row index,用高 3bits 作为 lookup table 的 column index,这样对128个 ASCII 字符建立如下的一个二维 bitmap table:
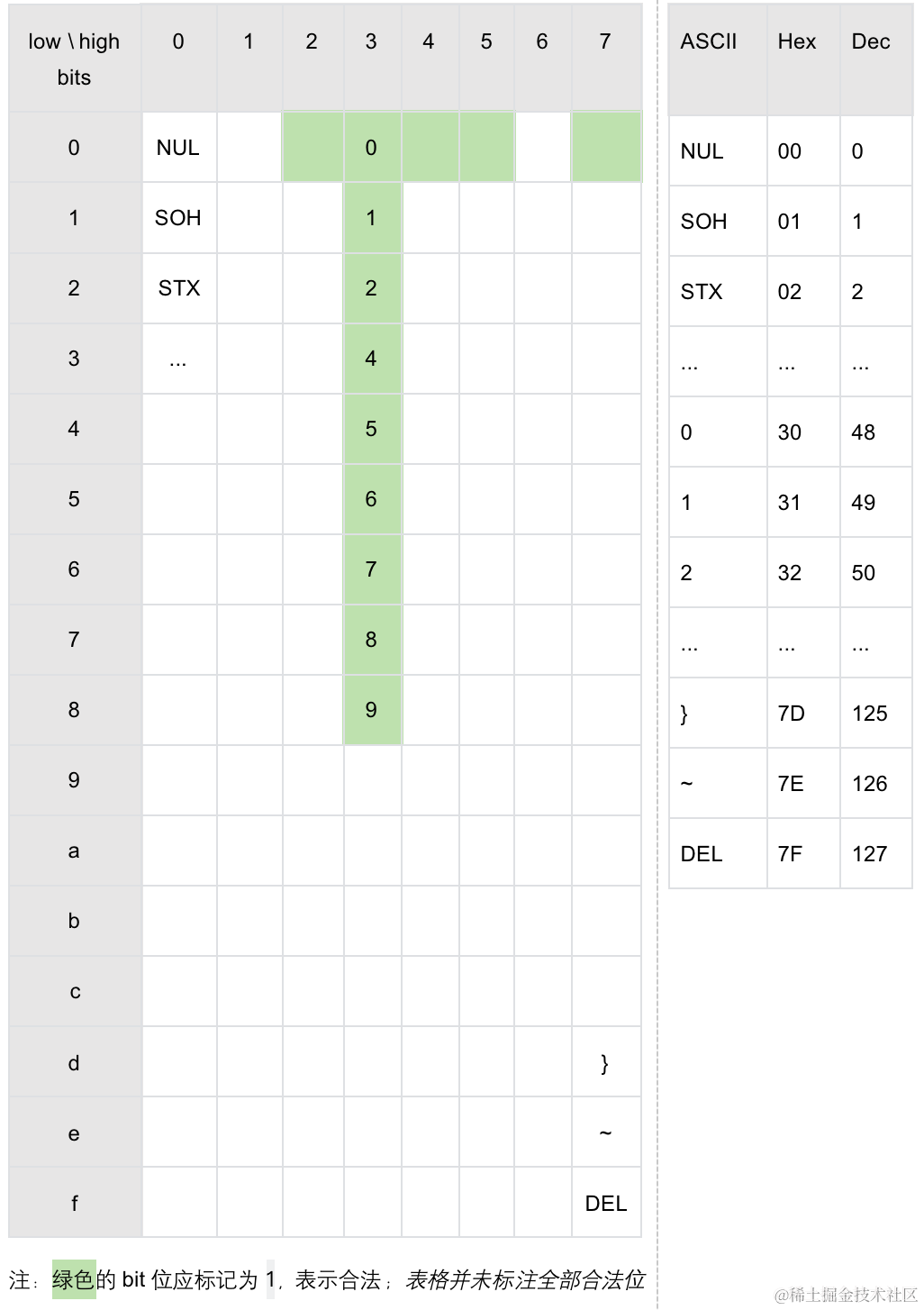
Lookup 流程
我们先实现一个纯 go 语言版本的基于二维 bitmap lookup table 的方案,以便于理解其中的关键逻辑:
table := [16]uint8{}
// fill flags
for i := 0; i < 128; i++ {if unicode.IsNumber(rune(i)) || unicode.IsLetter(rune(i)) || isRuneInWhiteList(rune(i)) {lowerNibble := i & 0x0fupperNibble := i >> 4table[lowerNibble] |= 1 << upperNibble}
}str := "hello"for _, char := range []byte(str) {if r > maxValidChar {return false}lowerNibble := uint8(r) & 0x0fupperNibble := uint8(r) >> 4if table[lowerNibble]&(1<<upperNibble) == 0 {return false}
}
return true如上代码示例,可以看到,判断某个字符合法的关键逻辑是:
通过 table[lowerNibble] 获取table第 lowerNibble 行内容,然后再看其第 upperNibble 个 bit 位是否为0
而 SIMD 版本,即是将上述的每一步操作都使用对应的 SIMD 指令变成对16个字节的并行操作,SIMD 的关键操作流程以及和上述 go 代码的对应关系如下:
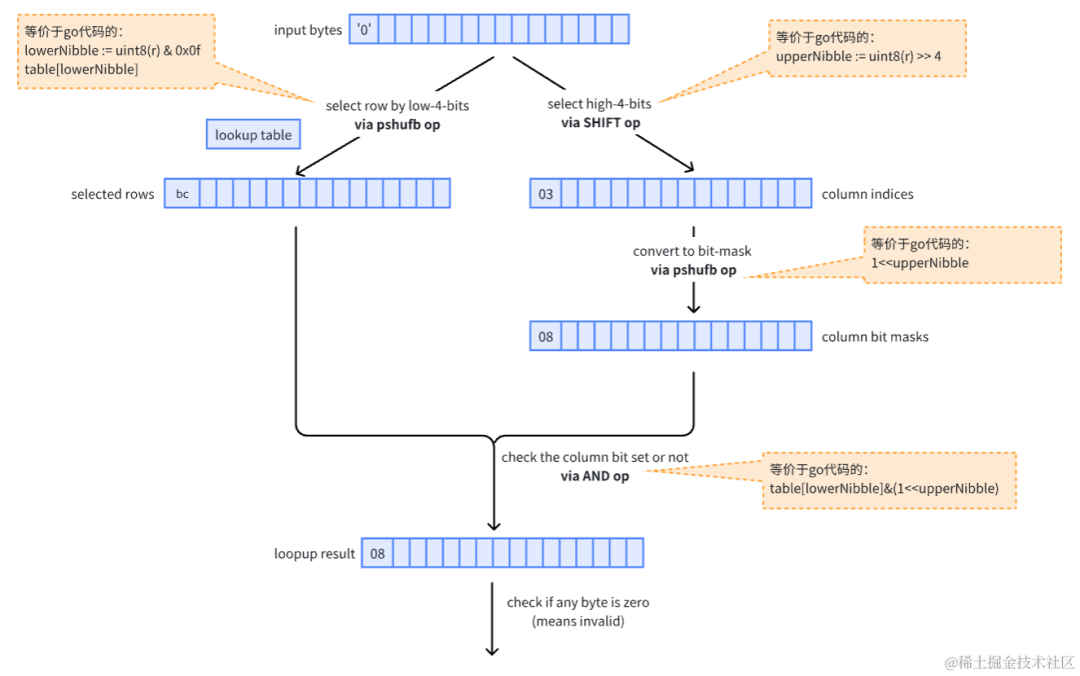
代码实现
在 go 语言中,想要使用 SIMD,需要写 plan9 汇编,而编写 plan9 通常有两种方式:
手撕,可借助 avo 这样的工具
C code 转 plan9,可借助 goat、c2goasm 这样的工具
这里采用 C code 转 plan9 的方式,先写一个 C 版本:
注:由于 goat 工具限制,不能很好的支持 C 代码中的常量定义,因此以下示例通过函数参数定义用到的 sm、hm 常量
#include <tmmintrin.h>// is_valid_string returns 1 if all chars is in table, returns 0 else.
void is_valid_string(char* table, char* strptr, long strlen, char* sm, char* hm, char* rt) {__m128i bitmap = _mm_loadu_si128((__m128i*)table);__m128i shift_mask = _mm_loadu_si128((__m128i*)sm);__m128i high_mask = _mm_loadu_si128((__m128i*)hm);size_t n = strlen/16;for (size_t i = 0; i < n; i++){__m128i input = _mm_loadu_si128((__m128i*)strptr);__m128i rows = _mm_shuffle_epi8(bitmap, input);__m128i hi_nibbles = _mm_and_si128(_mm_srli_epi16(input, 4), high_mask);__m128i cols = _mm_shuffle_epi8(shift_mask, hi_nibbles);__m128i tmp = _mm_and_si128(rows, cols);__m128i result = _mm_cmpeq_epi8(tmp, cols);size_t mask = _mm_movemask_epi8(result);if (mask != 65535) {*rt = 0;return;}strptr = strptr + 16;}size_t left = strlen%16;for (size_t i = 0; i < left; i++){size_t lower = strptr[i] & 0x0f;size_t higher = strptr[i] >> 4;if ((table[lower] & (1<<higher)) == 0) {*rt = 0;return;}}*rt = 1;return;
}通过以下命令转为 plan9:
goat is_valid_string.c -03 -mssse3生成的 plan9 代码如下:
//go:build !noasm && amd64
// AUTO-GENERATED BY GOAT -- DO NOT EDITTEXT ·_is_valid_string(SB), $0-48MOVQ table+0(FP), DIMOVQ strptr+8(FP), SIMOVQ strlen+16(FP), DXMOVQ sm+24(FP), CXMOVQ hm+32(FP), R8MOVQ rt+40(FP), R9WORD $0x8949; BYTE $0xd2 // movq %rdx, %r10LONG $0x3ffac149 // sarq $63, %r10LONG $0x3ceac149 // shrq $60, %r10WORD $0x0149; BYTE $0xd2 // addq %rdx, %r10LONG $0x0f428d48 // leaq 15(%rdx), %raxLONG $0x1ff88348 // cmpq $31, %raxJB LBB0_4LONG $0x076f0ff3 // movdqu (%rdi), %xmm0LONG $0x096f0ff3 // movdqu (%rcx), %xmm1LONG $0x6f0f41f3; BYTE $0x10 // movdqu (%r8), %xmm2WORD $0x894d; BYTE $0xd0 // movq %r10, %r8LONG $0x04f8c149 // sarq $4, %r8WORD $0xc031 // xorl %eax, %eaxLBB0_2:LONG $0x1e6f0ff3 // movdqu (%rsi), %xmm3LONG $0xe06f0f66 // movdqa %xmm0, %xmm4LONG $0x00380f66; BYTE $0xe3 // pshufb %xmm3, %xmm4LONG $0xd3710f66; BYTE $0x04 // psrlw $4, %xmm3LONG $0xdadb0f66 // pand %xmm2, %xmm3LONG $0xe96f0f66 // movdqa %xmm1, %xmm5LONG $0x00380f66; BYTE $0xeb // pshufb %xmm3, %xmm5LONG $0xe5db0f66 // pand %xmm5, %xmm4LONG $0xe5740f66 // pcmpeqb %xmm5, %xmm4LONG $0xccd70f66 // pmovmskb %xmm4, %ecxLONG $0xfffff981; WORD $0x0000 // cmpl $65535, %ecxJNE LBB0_8LONG $0x10c68348 // addq $16, %rsiLONG $0x01c08348 // addq $1, %raxWORD $0x394c; BYTE $0xc0 // cmpq %r8, %raxJB LBB0_2LBB0_4:LONG $0xf0e28349 // andq $-16, %r10WORD $0xb041; BYTE $0x01 // movb $1, %r8bWORD $0x294c; BYTE $0xd2 // subq %r10, %rdxJE LBB0_9WORD $0xc031 // xorl %eax, %eaxLBB0_7:LONG $0x1cbe0f4c; BYTE $0x06 // movsbq (%rsi,%rax), %r11WORD $0x8945; BYTE $0xda // movl %r11d, %r10dLONG $0x0fe28341 // andl $15, %r10dLONG $0x04ebc141 // shrl $4, %r11dLONG $0x0cbe0f42; BYTE $0x17 // movsbl (%rdi,%r10), %ecxLONG $0xd9a30f44 // btl %r11d, %ecxJAE LBB0_8LONG $0x01c08348 // addq $1, %raxWORD $0x3948; BYTE $0xd0 // cmpq %rdx, %raxJB LBB0_7LBB0_9:WORD $0x8845; BYTE $0x01 // movb %r8b, (%r9)BYTE $0xc3 // retqLBB0_8:WORD $0x3145; BYTE $0xc0 // xorl %r8d, %r8dWORD $0x8845; BYTE $0x01 // movb %r8b, (%r9)BYTE $0xc3 // retq对应的 Go Wrapper 代码如下:
var (// these runes are valid in tag valueswhiteListRunes = []rune{'_', '-', '.', '%', ':', ' ', '[', ']', ',', '%','/', ':', ';', '<', '=', '>', '@', '~'}rcBitTable [16]uint8smTable [16]int8hmTable [16]uint8
)//go:noescape
func _is_valid_string(table unsafe.Pointer, str unsafe.Pointer, len int32, sm, hm unsafe.Pointer, rt unsafe.Pointer)func init() {// build tablesfor i := 0; i < 128; i++ {if unicode.IsNumber(rune(i)) || unicode.IsLetter(rune(i)) || isRuneInWhiteList(rune(i)) {lowerNibble := i & 0x0fupperNibble := i >> 4rcBitTable[lowerNibble] |= 1 << upperNibble}}smTable = [16]int8{1, 2, 4, 8, 16, 32, 64, -128, 1, 2, 4, 8, 16, 32, 64, -128}hmTable = [16]uint8{0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f, 0x0f}
}func IsValidTagValueLookup2dBitTableSIMD(s string) bool {l := len(s)if l == 0 || len(s) > maxTagLen {return false}sptr := unsafe.Pointer((*reflect.StringHeader)(unsafe.Pointer(&s)).Data)var rt byte_is_valid_string(unsafe.Pointer(&rcBitTable), sptr, int32(len(s)), unsafe.Pointer(&smTable), unsafe.Pointer(&hmTable), unsafe.Pointer(&rt))return rt != 0
}Benchmark
先做一个通用的 benchmark,待校验的 string 长度从1 ~ 20不等:
goos: linux
goarch: amd64
pkg: code.byted.org/gopkg/metrics_core/utils
cpu: Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
BenchmarkLookupAlgoValid
BenchmarkLookupAlgoValid/baseline
BenchmarkLookupAlgoValid/baseline-8 2574217 510.5 ns/op
BenchmarkLookupAlgoValid/lookup-arraytable
BenchmarkLookupAlgoValid/lookup-arraytable-8 6347204 193.7 ns/op
BenchmarkLookupAlgoValid/lookup-2d-bittable-simd
BenchmarkLookupAlgoValid/lookup-2d-bittable-simd-8 6133671 185.2 ns/op可以看到,SIMD 版本在平均水平上与 arraytable 相当
由于 SIMD 优势主要体现在长字符串时,因此,我们使用一组长度为20左右的 string,再次 benchmark:
goos: linux
goarch: amd64
pkg: code.byted.org/gopkg/metrics_core/utils
cpu: Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
BenchmarkLookupAlgoValidLong
BenchmarkLookupAlgoValidLong/baseline
BenchmarkLookupAlgoValidLong/baseline-8 3523198 356.4 ns/op
BenchmarkLookupAlgoValidLong/lookup-arraytable
BenchmarkLookupAlgoValidLong/lookup-arraytable-8 8434142 153.3 ns/op
BenchmarkLookupAlgoValidLong/lookup-2d-bittable-simd
BenchmarkLookupAlgoValidLong/lookup-2d-bittable-simd-8 13621970 87.29 ns/op可以看到,在长 string 上 SIMD 版本表现出非常大的优势,相对于 arraytable 版本再次提升50%
结论
通过 lookup table + SIMD 的方式优化,字符校验的整体性能可以提升2~4倍
但由于在 Go 中 plan9 汇编无法内联,因此在待校验的字符串较短时不能体现其优势
Reference
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html#
http://0x80.pl/articles/simd-byte-lookup.html
https://fullyfaithful.eu/simd-byte-scan/
https://gorse.io/posts/avx512-in-golang.html#convert-assembly
http://0x80.pl/notesen/2016-04-03-avx512-base64.html
本文作者郭刚平,来自字节跳动 Dev Infra - APM - 观测数据引擎团队,我们提供日均数十PB级可观测性数据采集、存储和查询分析的引擎底座,致力于为业务、业务中台、基础架构建设完整统一的可观测性技术支撑能力。